HBase 0.90.5 發佈
資料來源:+NoSQL community in Luxembourg
Firefox 10 要在 2012 年推出(最近不是才出了 9 嗎? Orz),主要增加 HTML 跟 CSS 的設計輔助工具,例如 3-D page inspector 跟 built-in code editor,似乎意圖取代現在的 Firebug......?
資料來源:webmonkey
2011-12-30
2011-12-24
2011.12.24 短訊
主題:
短訊
這場演講裡頭提到 iPad2 的運算能力等於 1986 年 Cray 26 個處理器的超級電腦、可以在 20 年排進全世界運算能力前三名...... [核爆]。這篇文章是 PartyChat 如何將部份系統從 GAE 轉移到 EC2 上以對付 GAE 新價格政策,裡頭有蠻多實作與思路細節。最後這篇是 LinkedIn 把 IndexTank 這個技術 open source 了,IndexTank 是一個全文檢索搜尋的系統,提供 RESTful 的 API。其實今天 High Scalability 的 Stuff The Internet 超級長...... Orz
資料來源:High Scalability
提供 FF9(還在測試中)的 GWT Develop Mode Plugin 的下載點,以及 Google Group 上的討論。
資料來源:OIO Developer Blog
資料來源:High Scalability
提供 FF9(還在測試中)的 GWT Develop Mode Plugin 的下載點,以及 Google Group 上的討論。
資料來源:OIO Developer Blog
2011-12-21
2011.12.22 短訊
主題:
短訊
Firefox 9 release。這個版本在 JS 方面增加了 Type Interface,據說可以讓 JS 執行速度快上 20%~30%,另外也加強了 MemShrink project,據說吃 memory 的量比 Opera 11.60 還小。還有 fullscreen mode 可以把任何 HTML element 變成全螢幕、針對 Mac 的修改... 等等
資料來源:webmonkey
〈11 個程式界的趨勢〉這篇有點久了,不過現在才從別人的 G+ 看到。光看小標題就很有趣:「JVM 不只是給 Java 用」、「JS 不再只是 JS」、「頻寬與能源不再免費」、「正規教育逐漸不適用」...... 可細讀可淺嘗。資料來源底下還有一些關於 GWT 的討論。
資料來源:+Deanna Bonds
這篇在介紹(?)一個技術:In Memory Data Grid(IMDG),並列舉現有的 IMDG 產品選擇。我看不太出來 IMDG 跟 NoSQL 的差別(還是說其實是 In Memory 的 NoSQL?)...... Orz
資料來源:High Scalability
Spring Framework 搬到 GitHub 上......
資料來源:OIO Developer Blog
資料來源:webmonkey
〈11 個程式界的趨勢〉這篇有點久了,不過現在才從別人的 G+ 看到。光看小標題就很有趣:「JVM 不只是給 Java 用」、「JS 不再只是 JS」、「頻寬與能源不再免費」、「正規教育逐漸不適用」...... 可細讀可淺嘗。資料來源底下還有一些關於 GWT 的討論。
資料來源:+Deanna Bonds
這篇在介紹(?)一個技術:In Memory Data Grid(IMDG),並列舉現有的 IMDG 產品選擇。我看不太出來 IMDG 跟 NoSQL 的差別(還是說其實是 In Memory 的 NoSQL?)...... Orz
資料來源:High Scalability
Spring Framework 搬到 GitHub 上......
資料來源:OIO Developer Blog
2011.12.21 短訊
主題:
短訊
〈為甚麼 Dart 不打算用 Bytecode VM?〉裡頭分析了 bytecode VM 的優劣,並解釋為甚麼 Dart 要用 language VM。可能要對 Dart/JVM 的結構有點了解再看這篇會比較順(某人啜泣ing),整篇也有點像是在數落 JVM [炸]
資料來源:+Jeol Webber
Hibernate 4 release... 這好像已經是幾天前的消息了,因為沒在用(用 App Engine 的錢來省學 ORM 的時間? XD),所以也只是從消息來源當中看到......
資料來源:OIO Developer Blog
資料來源:+Jeol Webber
Hibernate 4 release... 這好像已經是幾天前的消息了,因為沒在用(用 App Engine 的錢來省學 ORM 的時間? XD),所以也只是從消息來源當中看到......
資料來源:OIO Developer Blog
2011-12-20
2011.12.20 短訊
主題:
短訊
解說 Twitter 的使用 MySQL 的儲存策略,包含舊的作法與新的作法(ㄜ... Twitter 不是說改用 NoSQL 嗎? 還是我記錯了?)。
資料來源:High Scalability
討論 CoffeeScript 到底是不是值得學習的「語言」,起因是 github 上的這篇文章,然後在 Hacker News 上有討論。github 的文章主要論調是說 CoffeeScript 並不是語言,而是 JavaScript 的一種(包含 design pattern、coding style)良好工具。Hacker News 的討論我沒看 [毆飛],因為 Ray Cromwell 的總結是:「The HackerNews thread neatly summarizes everything I dislike about language zealots, in particular, Javascript zealots.」
資料來源:+Ray Cromwell
列出目前 Java EE 6 App Server 的 release 日期、以及對應 support 的 JSR 列表。好久沒聽到 Resin 了,原來還活著 [毆飛]
資料來源:OIO Developer Blog
GPE 出 2.5 版,主要是整合 Cloud SQL 的開發工具。這篇這兩天會翻譯... [遠目]
資料來源:GAE Blog
資料來源:High Scalability
討論 CoffeeScript 到底是不是值得學習的「語言」,起因是 github 上的這篇文章,然後在 Hacker News 上有討論。github 的文章主要論調是說 CoffeeScript 並不是語言,而是 JavaScript 的一種(包含 design pattern、coding style)良好工具。Hacker News 的討論我沒看 [毆飛],因為 Ray Cromwell 的總結是:「The HackerNews thread neatly summarizes everything I dislike about language zealots, in particular, Javascript zealots.」
資料來源:+Ray Cromwell
列出目前 Java EE 6 App Server 的 release 日期、以及對應 support 的 JSR 列表。好久沒聽到 Resin 了,原來還活著 [毆飛]
資料來源:OIO Developer Blog
GPE 出 2.5 版,主要是整合 Cloud SQL 的開發工具。這篇這兩天會翻譯... [遠目]
資料來源:GAE Blog
2011-12-16
2011.12.17 短訊
主題:
短訊
M$ 終於設法讓 IE 6 說掰掰了...... 是說... 為甚麼你不乾脆讓中國古拳法 IE 系列在地球上消失咧......
資料來源:webmonkey
Grails 2.0 release... 也是一個沒在用的東西 [逃]
資料來源:OIO Developer Blog
資料來源:webmonkey
Grails 2.0 release... 也是一個沒在用的東西 [逃]
資料來源:OIO Developer Blog
2011-12-15
2011.12.15 短訊
主題:
短訊
Google+ 上有人列出 Google 使用 GWT 的產品列表,根據 Ray Cromwell 的資訊,他目前在 Google 上班、職稱是 GWT Hacker,之前 GwtQuake 就是他搞出來的,所以可信度應該不是問題。GMail(還有一些服務)不在裡頭還蠻令人傷心的 [淚目],反過來也可以印證〈GWT 與 Dart〉裡頭的說法,光 AdSense、AdWords 份量就很足夠了... \囧/
資料來源:OIO Developer Blog
另外... 今早起床的時候,發現 Buzz 從 GMail 上消失了...... [遠目]
資料來源:OIO Developer Blog
另外... 今早起床的時候,發現 Buzz 從 GMail 上消失了...... [遠目]
2011-12-14
2011.12.14 短訊
主題:
短訊
GAE 1.6.1 版發佈,這個打算後天完成中文翻譯,所以先跳過內容 [毆]
資料來源:GAE Blog
Firefox 8 目前還無法安裝 GWT Developer Plugin,這篇文章提供了直接殺進 SVN repository 的下載點。
資料來源:OIO Developer Blog
Chrome 16 版發佈,主要是提昇 chrome 的個人化同步功能,以前似乎只有 bookmark 有作同步,現在連 App、擴充套件、設定都會作同步。
資料來源:Google Chrome Blog
Spring 3.1 發佈...... 其實我沒在用這玩意 [逃]
資料來源:Spring Source Blog
資料來源:GAE Blog
Firefox 8 目前還無法安裝 GWT Developer Plugin,這篇文章提供了直接殺進 SVN repository 的下載點。
資料來源:OIO Developer Blog
Chrome 16 版發佈,主要是提昇 chrome 的個人化同步功能,以前似乎只有 bookmark 有作同步,現在連 App、擴充套件、設定都會作同步。
資料來源:Google Chrome Blog
Spring 3.1 發佈...... 其實我沒在用這玩意 [逃]
資料來源:Spring Source Blog
2011-12-13
2011.12.13 短訊
主題:
短訊
Electrolysis 是讓 Firefox 可以像 chrome 一樣,一個 process 處理一個 tab 的 project,目前宣佈暫停開發。裡頭有提到 chrome 這樣做的好處、以及為甚麼這個 project 暫停開發的原因。
資料來源:2ality.com
雖然《動畫聖堂》跟 Computer Science 沒有直接的關係,不過難得看到對另一個產業的詳細描述(通常都得看日本漫畫),老林還說「只要你看得懂中文就該讀一讀這篇文章」,故也在此推薦一下。(其實只是補今天短訊太短吧 [指])
資料來源:+Johnson Lin
資料來源:2ality.com
雖然《動畫聖堂》跟 Computer Science 沒有直接的關係,不過難得看到對另一個產業的詳細描述(通常都得看日本漫畫),老林還說「只要你看得懂中文就該讀一讀這篇文章」,故也在此推薦一下。(其實只是補今天短訊太短吧 [指])
資料來源:+Johnson Lin
2011-12-07
2011.12.07 短訊
主題:
短訊
〈Web開發中需要了解的東西〉這篇文章翻譯了 StackExchange 的〈What should every programmer know about web development?〉,並做了許多增加可讀性的註解。雖然有不少前端的東西 GWT 用不到(或是已經自動內建了),不過整體來說還是相當值得一看。
資料來源:CoolShell.cn
這篇短訊實在太短了,所以補一個前幾天才知道、已經 lag 有點久的消息,Objectify 在 2011.11.10 release 3.1 版。
資料來源:CoolShell.cn
這篇短訊實在太短了,所以補一個前幾天才知道、已經 lag 有點久的消息,Objectify 在 2011.11.10 release 3.1 版。
2011-11-29
2011.11.29 短訊
主題:
短訊
資料來源:http://coolshell.cn/articles/6010.html
裡頭提到一個大學講師寫的演算法實作列表:http://www.keithschwarz.com/interesting/。我想,台灣絕大多數的資訊系學生(絕對包含我在內),或許也包括一定比率的資訊系教授,看到這個網站都應該感到羞愧。
如果你還在資訊系/所唸書,還是找個時間手動刻個 Linked List 之類的基礎 data structure 吧!尤其是學 Java 的人,用 Java 寫這些東西真的很輕鬆了,還可以複習 OO 觀念......
資料來源:http://googleblog.blogspot.com/2011/11/evolution-of-search-in-six-minutes.html
講 Google Search 的預計演進。內容其實就還好,比較吸引我的是 http://www.google.com/insidesearch/index.html#timeline 的展示手法。
資料來源:http://googleblog.blogspot.com/2011/11/five-tips-for-stress-free-holiday.html
以 Google 的角度展示如何整合 Google 資源來線上購物。搭配 ET Blue 在 Google+ 發表的〈賣場 Android apps 試用報告〉,以及底下的 comment,對台灣的人而言應該別有一番風味...... [炸]
突然很想嘆氣......
裡頭提到一個大學講師寫的演算法實作列表:http://www.keithschwarz.com/interesting/。我想,台灣絕大多數的資訊系學生(絕對包含我在內),或許也包括一定比率的資訊系教授,看到這個網站都應該感到羞愧。
如果你還在資訊系/所唸書,還是找個時間手動刻個 Linked List 之類的基礎 data structure 吧!尤其是學 Java 的人,用 Java 寫這些東西真的很輕鬆了,還可以複習 OO 觀念......
資料來源:http://googleblog.blogspot.com/2011/11/evolution-of-search-in-six-minutes.html
講 Google Search 的預計演進。內容其實就還好,比較吸引我的是 http://www.google.com/insidesearch/index.html#timeline 的展示手法。
資料來源:http://googleblog.blogspot.com/2011/11/five-tips-for-stress-free-holiday.html
以 Google 的角度展示如何整合 Google 資源來線上購物。搭配 ET Blue 在 Google+ 發表的〈賣場 Android apps 試用報告〉,以及底下的 comment,對台灣的人而言應該別有一番風味...... [炸]
突然很想嘆氣......
2011-11-28
我所用的免費開發工具
「如果開發工具就是要我們付一堆錢,那我就讓你們看見窮人的驕傲」
- JavaSE:從 Sun 到 Oracle,至少官方的 JVM 與 SDK 都還是免費下載使用。
- Eclipse:以 Java Programmer 來說,這是一套很完整的 IDE。code assist、JavaDoc...... 到 Refactory 的功能(自從有了 rename 功能之後,變數名稱都可以亂取了呢... [毆飛])都無須安裝 plugin 就具備。如果以「我只是想寫個簡單的 Java」角度來說,可能還會有點嫌棄裡頭有太多東西了(瞧瞧那精美的 Ant、Maven、Mylyn......)
- Google Plugin for Eclipse(GPE):包含 GWT、GAE 的 SDK 與 GAE 的 local runtime 以及整合 GWT 的 deploy 工具。GWT 裡頭還提供了 GWT Designer 這個處理 layout 的 UI 工具。現在還整合 Google Code、Google API....... 統統不用錢。btw... 其實 GWT Designer 本來是商業軟體,後來被 Google 買下來之後就......
再加上用 Google Doc (算是能)解決 M$ Office 的檔案問題,買 Notebook 本來就附贈 Windows 的版權(我沒厲害到想去用 Linux 或是 Mac),電腦打開來,還真的沒什麼值錢的軟體......
這就是窮人的驕傲 [炸]
2011-11-23
2011.11.23 短訊
主題:
短訊
資料來源:http://googleblog.blogspot.com/2011/11/more-spring-cleaning-out-of-season.html
- Google Bookmark List 會在 12.19 結束,但是 Google Bookmark 的其他功能不會受到影響。
- Google Friend Connect 轉向處理 Google+ Page、以及有 Google+ badge 的網站
- Google Gears 將全面停止使用,改使用 HTML5
- 移除 Google Search Timeline,改使用 Google Trends 或 google.com/insights/search/
- Google Wave 在 2012.01.31 改成唯讀、2012.04.30 徹底關掉。如果想要用類似的服務,可以到 Apache Wave 或是 Walkaround。
- Knol 將在 2012.05.01 之後停止使用,在這隻前可以下載並轉換到 WordPress.com 的 http://annotum.org/ (譯註:選擇 WordPress 真是十分有趣 )
2011-11-22
Don'tCare Blog
主題:
想法與作法
我退伍前騙到了一點錢,於是跟前同事 dirtyeye 成立了 Don'tCare 工作室:http://DontCareAbout.us。
雖然到現在連一個正式的案子都還沒有,不過有些存在已久的想法倒是很努力的付諸實行,其中之一就是「每個月至少寫一篇技術性文章」,然後放到 Don'tCare Blog 上以顯示自己的技術與文筆有多麼落後。
至於 Don'tCare Blog 跟 PT2Club Blog 有什麼差異?會怎麼規劃?
主要的差異是 Don'tCare Blog 會多出 dirtyeye 寫的文章(應該會偏美術設計方面),而以後工作相關的文章(GWT、GAE 等),我會改在 Don'tCare Blog 上發表。至於 PT2Club Blog 這邊,目前還沒什麼特別的想法,畢竟能力有限、光解決工作上的需求都有點疲乏了,很難再兼顧其他領域。有打算改張貼網路文章提要,實際上... 再看看吧...... XD
報告完畢
雖然到現在連一個正式的案子都還沒有,不過有些存在已久的想法倒是很努力的付諸實行,其中之一就是「每個月至少寫一篇技術性文章」,然後放到 Don'tCare Blog 上
至於 Don'tCare Blog 跟 PT2Club Blog 有什麼差異?會怎麼規劃?
主要的差異是 Don'tCare Blog 會多出 dirtyeye 寫的文章(應該會偏美術設計方面),而以後工作相關的文章(GWT、GAE 等),我會改在 Don'tCare Blog 上發表。至於 PT2Club Blog 這邊,目前還沒什麼特別的想法,畢竟能力有限、光解決工作上的需求都有點疲乏了,很難再兼顧其他領域。有打算改張貼網路文章提要,實際上... 再看看吧...... XD
報告完畢
2011-11-15
GWT 與 Dart
原文網址:http://googlewebtoolkit.blogspot.com/2011/11/gwt-and-dart.html
最近,Google Web Toolkit 團隊被問到:對於幾個星期前發表的 Dart 程式語言,有什麼後續的計畫?
Dart 與 GWT 的目標是相同的:實現結構化的 web 開發方式。事實上,有許多製造出 GWT 的工程師正在建構 Dart。在「GWT 的目標:對終端使用者而言,讓 Web Application 變得更好」這點上,我們認為 Dart 是有企圖心的演進,看好 Dart 的潛力。在 Dart 逐漸發展並為黃金時段(譯註:不懂)做好準備的同時,我們期望與 GWT 開發社群緊密合作來探索 Dart。
也請放心,如果你要創造野心勃勃的 web application、甚至是像憤怒鳥的遊戲,GWT 會持續是個高產能且可信賴的選擇。Google 裡重要的 project 每天都依賴著 GWT 來開發,我們計畫依照他們的實際需求來不斷改進(並 open source)GWT。
最近,Google Web Toolkit 團隊被問到:對於幾個星期前發表的 Dart 程式語言,有什麼後續的計畫?
Dart 與 GWT 的目標是相同的:實現結構化的 web 開發方式。事實上,有許多製造出 GWT 的工程師正在建構 Dart。在「GWT 的目標:對終端使用者而言,讓 Web Application 變得更好」這點上,我們認為 Dart 是有企圖心的演進,看好 Dart 的潛力。在 Dart 逐漸發展並為黃金時段(譯註:不懂)做好準備的同時,我們期望與 GWT 開發社群緊密合作來探索 Dart。
也請放心,如果你要創造野心勃勃的 web application、甚至是像憤怒鳥的遊戲,GWT 會持續是個高產能且可信賴的選擇。Google 裡重要的 project 每天都依賴著 GWT 來開發,我們計畫依照他們的實際需求來不斷改進(並 open source)GWT。
2011-10-27
GWT 2.4.0 需搭配 gwt-maps 1.1.1rc1
雖然這篇文章可能一兩個月後就沒啥鳥用,但是為了這點鳥事搞了一個下午,還是寫篇文章以供日後緬懷...... [遠目] (其實根本就是想點擊率吧? [指])
故事的前情提要是我想要透過 Google Maps API 作一些壞事,但是用 JavaScript 做起來實在不夠愉快,更不用說有些東西已經偷懶用 JSP 控制還是不能徹底解決問題。好吧,那就徹底 Java 到底,透過 gwt-google-api 的 Maps 來惡搞。
故事的前情提要是我想要透過 Google Maps API 作一些壞事,但是用 JavaScript 做起來實在不夠愉快,更不用說有些東西已經偷懶用 JSP 控制還是不能徹底解決問題。好吧,那就徹底 Java 到底,透過 gwt-google-api 的 Maps 來惡搞。
2011-10-12
App Engine 1.5.5 版發佈
App Engine 在 2011 年釋出了一些令人興奮的版本。隨著白天越來越短、天氣越來越冷、雜貨店裡頭的萬聖節糖果開始引誘人變胖,我們也一直努力讓最新的版本能順利推出。
高級帳戶
在為最關鍵的商業 application 選擇運作平台時,我們認為「保證可運行時間」、「管理容易」與「付費的支援」跟產品的功能一樣重要。 因此,我們開始推出 Google App Engine 的高級帳戶。每月支付 500 美元(不包含 internet service 的費用),將會下列這些功能:
支援 Python 2.7 版
PIL?NumPy?concurrent request?這些 Python 2.7 版全部都有。今天我們實驗性地開放支援 Python 2.7 版。2.7 與 2.5 版執行環境的差異,我們已經都放到已知差異整理列表當中。
整體性的更新
我們知道卡在硬性的系統限制當中是多麼令人沮喪的事情,所以今年一整年持續在提昇我們的系統限制。在這個版本當中,我們又擴增了一些東東:
高級帳戶
在為最關鍵的商業 application 選擇運作平台時,我們認為「保證可運行時間」、「管理容易」與「付費的支援」跟產品的功能一樣重要。 因此,我們開始推出 Google App Engine 的高級帳戶。每月支付 500 美元(不包含 internet service 的費用),將會下列這些功能:
- 專屬的技術支援服務(細節參閱技術支持服務指南)。
- 「保證 service 在 99.95% 的時間中是可運作」協定(參閱協定草稿,最終版會 be in the signed offline agreement)。
- 在高級帳戶的 domain 下,applicaion 的數量沒有上限。
- 每個 application 沒有最低月租費,只要負擔你所使用的 resource 費用就好。
- 以發票按月結算。
支援 Python 2.7 版
PIL?NumPy?concurrent request?這些 Python 2.7 版全部都有。今天我們實驗性地開放支援 Python 2.7 版。2.7 與 2.5 版執行環境的差異,我們已經都放到已知差異整理列表當中。
整體性的更新
我們知道卡在硬性的系統限制當中是多麼令人沮喪的事情,所以今年一整年持續在提昇我們的系統限制。在這個版本當中,我們又擴增了一些東東:
- request 的持續時間:前端 request 的 deadline 已經從 30 秒增加到 60 秒。URLFetch 的最大 deadline 也從 10 秒增加到 60 秒。
- 檔案限制:我們增加了一個 application 所能上傳的(靜態)檔案數量,從 3000 增加到 10000,並且大小的限制也從 10MB 增加到 32MB。
- API 限制:現在 URLFetch 的 Post payload 上限從 1MB 改為 5MB。
- Cloud SQL:我們上週宣布在 App Engine 中支援 SQL。請試試看,並告訴我們你的想法。
- 全文檢索:我們正在找尋前期的委託測試者,來測試期望很久的全文搜尋 API。如果你有興趣嘗試它,請填寫這個表格。
- Conversion API:曾想要在 application 當中將文字輸出成 PDF 嗎?請考慮報名成為 Conversion API 的委託測試者。
- Cross Group(XG)Transaction:對於需要對多個 entity group 的 entity 作寫入 transaction 的人(其實就是每個人吧?),那就用 XG Transcation 吧。 這個功能需要兩段式的 commit,好讓跨 group 的 write atomic 可以就像單一 group 的寫入行為。
- 實驗階段的整合 Google Cloud Storage:從前開發人員稱為 Google Storage 的 Google Cloud Storage 脫離 lab 階段了,我們正透過增加「用 File API 存取」的方式加強整合性。
- Prediction API:另一個脫離 lab 階段的東東是 Prediction API。可以到它們的入門指南看一些 App Engine 上的範例。
2011-10-08
Google Cloud SQL:你的雲端資料庫
原文網址:http://googleappengine.blogspot.com/2011/10/google-cloud-sql-your-database-in-cloud.html
「提供一個可以簡單開發傳統資料庫應用程式的方法」是最常要求 App Engine 提供的功能之一。為了回應這些聲浪,我們很高興地宣佈 Google Cloud SQL 有限制地開放試用。現在你可以選擇讓 App Engine 的 application 使用完全在雲端當中但卻是熟悉的 relational database。這讓你能專注在開發 application 與 service,至於管理、維護 relational database 的雜事統統不用管。Google Cloud SQL 帶給 App Engine 社群許多好處:
- 不用維護、也不用管理——我們都幫你處理了。
- 高可靠度與可用度——你的資料會同步複製到多個 data center。機器、機架與 data center 的故障都會自動處理,盡可能地避免影響到 end user。
- 熟悉的 MySQL database 環境,有支援 Java 的 JDBC、也有支援 Python 的 DB-API。
- 綜合式的管理 database 使用者介面。
- 簡單卻完全與 App Engine 整合。
這個 service 也包括了 database 匯入/匯出的功能,所以你可以把你既有的 MySQL 送上雲端,然後在 App Engine 當中使用。Cloud SQL 現在是免費提供,我們會在至少開始收費前 30 天公佈價格。在我們解決初期大小問題的同時也會持續改進這個 service,如果你想拿來試試看,請讓我們知道。
2011-09-28
用 Channel API 實作簡易聊天室
Google App Engine 自 1.4.0 版推出 Channel API,使 server 與 browser 之間可以不透過 pooling 的方式做到 server push。不過 Google 官方教學文件摻雜了井字遊戲的元素,反而無法專注於 Channel API 上。這篇文章打算用最原始的聊天室,透過實做的過程來體驗一下 Java 版 Channel API。
因為是簡易聊天室,所以只打算提供一個共用的聊天室,然後用兩個 JSP 檔來解決:room.jsp、server.jsp。room.jsp 負責處理使用者輸入訊息、顯示對話;server.jsp(應該寫成 servlet 比較好,因為是簡易聊天室......)負責接收訊息、並廣播出去。
對應到 Channel API 的用詞,一個聊天室就是一個 channel,同一個 channel 的成員(client 端)就會接收到其他成員所發出的訊息(message)。所以,從 server 的角度,需要作這些事情:
因為是簡易聊天室,所以把名稱訂死為「PsMonkey」。產生 token 的方法是:
因為是簡易聊天室,所以把 token 透過 JSP 產生、並塞進 client 端的 JavaScript 碼。
接下來看 client 端的部份。首先建立連線的部份:
socket 就是實際處理通訊的部份。這段的重點是透過 handler 設訂 socket 各種狀況會觸發的 method。仔細想一下就會發現:「只有接收訊息的 method,那傳送訊息呢?」
Channel API 要解決的問題是 server push,client 端傳送訊息的功能並不包含在其中,得透過 HTTP request 來作到。所以送訊息的 method 會長的像這樣:
於是用 sendMessage() 來設定在 client 端連線時送出「____ 進入聊天室」、離線時送出「____ 離開聊天室」:
有訊息進來的時候,就把訊息塞進某一個 element 的尾巴。這邊要注意一點,參數 msg 不是單純的字串,而是一個物件,data 這個 field 才是真正回傳的資料。
接著來看一下負責處理 client 端 sendMessage() 的 server.jsp,直接貼程式碼:
在從 request 當中取得 clinet 端傳上來的訊息後,連同 channel 的名稱包成一個 ChannelMessage,透過 ChannelService.sendMessage() 傳出去,就會觸發 client 端的 socket.onMessage 了。
再透過一些簡單的 HTML 與 JavaScript 來讓 client 端送出訊息時能呼叫到 sendMessage(),聊天室就完成了!是不是很簡單呢? [扭扭]
最後補充 socket 的幾件事情:
對應到 Channel API 的用詞,一個聊天室就是一個 channel,同一個 channel 的成員(client 端)就會接收到其他成員所發出的訊息(message)。所以,從 server 的角度,需要作這些事情:
- 開啟一個 channel
- 給加入這個 channel 的 client 專屬識別碼(token)
- 接收訊息的管道
- 發送訊息的功能
//Java code
ChannelService channel = ChannelServiceFactory.getChannelService();
String token = channel.createChannel("PsMonkey");
接下來看 client 端的部份。首先建立連線的部份:
//JavaScript code
var channel = new goog.appengine.Channel("<%=token%>"); //token 傳入
var handler = {
'onopen' : onOpened, //建立連線、channel.open() 就會觸發
'onmessage' : onMessage, //有訊息傳入時
'onerror' : onError, //發生錯誤時
'onclose' : onClosed, //連線結束時
};
socket = channel.open(handler);
socket 就是實際處理通訊的部份。這段的重點是透過 handler 設訂 socket 各種狀況會觸發的 method。仔細想一下就會發現:「只有接收訊息的 method,那傳送訊息呢?」
Channel API 要解決的問題是 server push,client 端傳送訊息的功能並不包含在其中,得透過 HTTP request 來作到。所以送訊息的 method 會長的像這樣:
//JavaScript code
sendMessage = function(message) {
var xhr = new XMLHttpRequest();
xhr.open('POST', 'server.jsp?msg='+message, true);
xhr.send();
};
於是用 sendMessage() 來設定在 client 端連線時送出「____ 進入聊天室」、離線時送出「____ 離開聊天室」:
//JavaScript code
onOpened = function() {
sendMessage("「"+name + "」進入聊天室......");
};
onClosed = function(){
sendMessage("「"+name + "」離開聊天室......");
}
有訊息進來的時候,就把訊息塞進某一個 element 的尾巴。這邊要注意一點,參數 msg 不是單純的字串,而是一個物件,data 這個 field 才是真正回傳的資料。
//JavaScript code
onMessage = function(msg) {
document.getElementById("output").innerHTML += msg.data +"<br />";
}
接著來看一下負責處理 client 端 sendMessage() 的 server.jsp,直接貼程式碼:
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
<%@page import="com.google.appengine.api.channel.*"%>
<%
String message = request.getParameter("msg");
ChannelService channel = ChannelServiceFactory.getChannelService();
channel.sendMessage(
new ChannelMessage("PsMonkey", message)
);
%>
在從 request 當中取得 clinet 端傳上來的訊息後,連同 channel 的名稱包成一個 ChannelMessage,透過 ChannelService.sendMessage() 傳出去,就會觸發 client 端的 socket.onMessage 了。
再透過一些簡單的 HTML 與 JavaScript 來讓 client 端送出訊息時能呼叫到 sendMessage(),聊天室就完成了!是不是很簡單呢? [扭扭]
最後補充 socket 的幾件事情:
- onerror 會傳入一個參數,其中有兩個 field:
- description:錯誤的描述
- code:HTTP 錯誤代碼
- 目前只測出 idle 太久、server 切斷連線時會觸發
- socket 還有一個 method:close(),呼叫成功會觸發 socket.onclose。
2011-09-16
App Engine 1.5.4 版發佈
原文網址:http://googleappengine.blogspot.com/2011/09/app-engine-154-sdk-release.html
這四個禮拜真的是忙翻啦(你可能有聽說),但我們仍然保持每個月發佈新版本的期程。今天我們提供了新的 SDK,以及一些新功能和錯誤修正。
整體更新
- Blobstore API——我們加入了一個選項,讓你可以指定上傳 blob 的大小限制。這個功能讓你可以接觸到使用者上傳的 blob,同時也可以確保他們上傳的東西沒有超過你預設的限制。
- Datastore 查詢改進——我們延續過去幾個版本的主題,調整 Datastore 的查詢規劃,讓使用者感覺更靈活。從 1.5.4 版開始,對多個 property 作 filter 的查詢,會持續運作直到 Datastore 的查詢時間上限(高達 30 秒!)。過去,許多這類的查詢都會因為沒有效率的 index 而導致產生錯誤,現在則會運作正常。
- 在 SDK 中顯示 Datastore 寫入次數——依據最近改版為 Side by Side 帳單時所得到的回饋意見,現在我們會在 SDK 的 dataviewer 當中顯示儲存一個 entity 需要的寫入次數。寫入的次數包含寫入 entity、以及增加 entity 時 index 的寫入。你可以透過把 index 的 property 調整成 unindex 的 properties,來降低寫入的次數,只要確定你沒有在其他 query 當中參考到這些 property 就好。(參考 Java 與 Python 的相關 API)
- Prospective Search API——我們發佈了實驗性質、Java 版本的 Prospective Search API。這讓你在符合某些條件的資料被寫入到 Datastore 時,能偵測到、並有所作為。
- Memcache——你現在可以非同步呼叫 Memcache API。有了非同步的 Memcache,你的 application 就不會在呼叫 Memcache 時被 block 住,可以繼續處理 request 而不用等待 Memcache 的回應。寫 Java 的朋友們也不要擔心,我們即將釋出的版本會有對應的功能。
2011-09-08
App Engine 1.5.3 版發佈
原文網址:http://googleappengine.blogspot.com/2011/08/app-engine-153-sdk-released.html
今天,我們很高興地宣佈新版的 App Engine 發佈了。你可能有注意到,在過去幾個月中,版本更新的頻率略有上升。我們做了一些內部改組,期待能每個月推出一個新版本。這個月的更新包含了一些 datastore 的更新、一些 blobstore API、memcache API 的更新,以及一個針對 Java 開發者的新功能。
Python 與 Java 的改變
- blobstore API——我們已經取消 blob 上傳的大小限制。你現在可以上傳任何大小的檔案,讓你的 application 可以處理圖片、影片、或任何 internet 連線可以處理的東西。
datastore 的改變
- 取回索引——對現存於 datastore 的索引,我們加上了讓你可以用程式取回索引列表及狀態的功能。
- datastore 管理——現在你可以在 Admin Console 啟用 datastore 管理功能。這讓 Java 使用者可以做到「刪除某一類下的所有 entity」的功能,而無須上傳 Python 版的 application。對於 Python 的開發人員而言,這表示你不用再到 app.yaml 檔裡頭將這個功能開啟。
- HRD 整合的可靠測試者——我們正在找尋前期就採用 HRD 的人,來實驗強化 HRD 整合的工具。這個工具需要一段唯讀時間,這段時間與你的 datastore 寫入頻率有關(目前這個版本的行為是相對於 datastore 的大小)。請參閱版本更新紀錄,裡頭有更多資訊。(謎之聲:這是哪門子的版本更新 ==")
Python 的更新
- memcache API——我們在 Python 的 memcache API 當中支援 CAS(compare-and-swap,比較並替換)的操作方式(Java 已經有了)。當你取值回來並要更新它時,這個操作讓你可以在沒有其他更新的 request 時,才作更新的動作。
Java 的更新
- 下載 application——使用 AppCfg download_app 指令,你可以下載上次更新版本當中,war 目錄下的任何檔案。
這個版本還包含一些微幅的更新與錯誤修正(無論是 Python 版或 Java 版),所以一定要參閱完整的版本更新紀錄。回饋意見與問題討論都可以在我們的 Google Group 當中發表。
2011-09-06
App Engine 1.5.2 版發佈
原文網址:http://googleappengine.blogspot.com/2011/07/app-engine-152-sdk-released.html
server 產能的更新
Datastore 的更新
Task Queue 的更新
最後,我們有一些令人振奮的消息是關於實驗中 Go 執行環境。雖然 Go 仍然在實驗階段,但從 1.5.2 之後,Go 將可以存取所有 HRD 的 application。
一如往常,也有一些小功能與錯誤修復,在我們的版本更新紀錄當中可以找到完整的清單(Python 版,Java 版)。我們期待在論壇當中看到您的回饋意見與問題。
server 產能的更新
- 可調整的 Scheduler 參數 - 正如之前討論過,我們推出了兩款 scheduler 旋鈕(好吧,實際上看起來比較像滑動軸),讓你能控制有多少 instance 在 application 上執行的參數。現在,你將可以設定 panding latency 的最小值、以及閒置 instance 的最大量。
Datastore 的更新
- 進階 query 計畫 - 我們移除了爆量索引的需要、也減少了許多 query 要自訂 index 的需求。在許多狀況下 SDK 會建議更佳的索引方式,接下來的文章也會介紹如何進一步最佳化。
- namespace 層級的 datastore 統計資料:現在除了取得全部的 datastore 統計資料,我們也提供一個新的選擇,讓你可以以 namespace 來查詢。
Task Queue 的更新
- 新的 Task Queue 細目頁面——我們改寫了 Administration Console 裡的 Task Queue 細目頁面,提供了執行中的 task 的更多資訊。你現在可以看到排隊中的 task、有效承載量、以及前一個執行 task 的資料。
- 1MB 的 Pull Task 容量——對於容量大小的限制,我們的信念就是:只能變得越來越大!所以,在這個版本當中,我們把 Pull Task 的容量變成 1MB。
- Pull Queue 時效變更——針對 Pull Queue 我們推出了新的 method,如果當初設定的時效不足時,讓你可以將現有的 task 延長時效。
最後,我們有一些令人振奮的消息是關於實驗中 Go 執行環境。雖然 Go 仍然在實驗階段,但從 1.5.2 之後,Go 將可以存取所有 HRD 的 application。
一如往常,也有一些小功能與錯誤修復,在我們的版本更新紀錄當中可以找到完整的清單(Python 版,Java 版)。我們期待在論壇當中看到您的回饋意見與問題。
2011-09-04
整合 GMail 帳號
我有四個常用的 GMail 帳號。
當然,GMail 早就不是邀請制了,甚至自己弄個 Google Apps,要有幾個帳號都不是問題。事實上,因為 Google 的 service 用得有點兇,從 GMail、Blogger、Reader、Sites、WebMaster、譯者工具包還有賺錢用的 AdSense,我還寧願只用一個帳號就滿足全部需要。
大多數的 service 的確可以做到,像 Blogger 這種寫作類的 service 都有提供其他作者協同寫作的功能、Reader 用匯入匯出的功能解決,剩下的 WebMaster 跟 AdSense 偶爾上去看一看(似乎也能開放給其他帳號,沒細究),倒也還過得去。
不過 GMail 就沒這麼簡單了,總不能用公司的帳號收信、卻用私人的帳號回信吧?所以之前的作法是同時開 Chrome 跟 Firefox,搭配無痕/私密瀏覽來解決......
後來經高人指點,發現 GMail 早就想到這點了,還提供了兩個招數......
萬用基本招:POP + Send mail as
GMail 裡頭要把 A 帳號的信都轉到 B 帳號有兩種方法。第一種是選擇轉寄(Forwarding)、第二種是透過 POP3 取得信件。這裡建議是用 POP3 的方式,步驟如下:
當然,GMail 早就不是邀請制了,甚至自己弄個 Google Apps,要有幾個帳號都不是問題。事實上,因為 Google 的 service 用得有點兇,從 GMail、Blogger、Reader、Sites、WebMaster、譯者工具包還有賺錢用的 AdSense,我還寧願只用一個帳號就滿足全部需要。
大多數的 service 的確可以做到,像 Blogger 這種寫作類的 service 都有提供其他作者協同寫作的功能、Reader 用匯入匯出的功能解決,剩下的 WebMaster 跟 AdSense 偶爾上去看一看(似乎也能開放給其他帳號,沒細究),倒也還過得去。
不過 GMail 就沒這麼簡單了,總不能用公司的帳號收信、卻用私人的帳號回信吧?所以之前的作法是同時開 Chrome 跟 Firefox,搭配無痕/私密瀏覽來解決......
實在有夠土砲的...... Orz
後來經高人指點,發現 GMail 早就想到這點了,還提供了兩個招數......
萬用基本招:POP + Send mail as
GMail 裡頭要把 A 帳號的信都轉到 B 帳號有兩種方法。第一種是選擇轉寄(Forwarding)、第二種是透過 POP3 取得信件。這裡建議是用 POP3 的方式,步驟如下:
- 進入 A 帳號,將「POP 下載(POP Download)」的功能開啟。
- 進入 B 帳號,在「從其他帳戶取得郵件(check mail using POP3)」新增一個帳號。這裡要注意一點,如果 A 帳號不是 xxx@gmail.com,而是由 Google Apps 提供的,記得在「使用者名稱」輸入完整的 email 帳號。另外 POP 伺服器就輸入「pop.gmail.com」、通訊埠選擇「995」
設定完成後,系統就會開始到 A 帳號檢查有無信件,有的話會抓回來並掛上對應(可設定)的標籤。
如果 Google 只做到這邊,那也不過就是功能稍微強一點 web 版的郵件軟體。重點在於「Send mail as」的功能,這功能在設定完「POP 下載」應該就會出現,也可以獨立設定。這是幹什麼的呢?它可以讓你用 B 帳號登入寄信,但是收信人看到的寄信者卻是 A 帳號。
如此,透過 POP 將另一個帳號的信彙整進來、寄信的時候可以用指定的帳號寄出去,事情解決了,萬歲! \囧/
萬能大絕招:Grant access to your account
萬用基本招雖然解決了,可是總覺得還是哪裡不滿足。最根本的問題是通訊錄:A 帳號的通訊錄得透過匯入匯出的方式才能帶到 B 帳號(雖然說回信之後會自動建立通訊錄),而且很容易就會變成公私不分的大雜燴。再者就是信件得依賴標籤的功能來區分,看/找起來並不是那麼快樂。有沒有更簡單的方式呢?
當然有!
在 A 帳號的「授權這些使用者存取我的帳戶(Grant access to your account)」增加 B 帳號的資訊,過一段時間(號稱半個小時)之後重新登入 B 帳號,就可以點選畫面右上角顯示帳號的地方,選擇「切換帳號」會出現 A 帳號,再點下去會另外開一個視窗...... YES! 直接變成 A 帳號登入的畫面了!
是的,除了沒有 Buzz、Chat、Calendar 這些 mail 以外的功能,其餘畫面操作跟 A 帳號登入時一模一樣。A、B 帳號可以同時掛在同一個瀏覽器底下,而且不用知道/輸入 A 帳號的密碼。另外,要同時代管幾個帳號也都不是問題、完全不會混亂。
不過這招有個限制,就是 A、B 兩個帳號的 domain name 必須是一樣的,foo@gmail.com 跟 mail@foo.com 是無法這樣設定的。
心得感想
不管是從哪個角度來看,都是感觸良多。
從軟體開發的角度,只能說自嘆不如。當然,上頭說得這些功能並不需要什麼高深的技術或演算法,問題在於細節很多:得同時兼顧方便性與安全性、還不能造成使用上的混亂與衝突,如果連版本演進的功夫一起算下去,Google 在軟體架構設計上真的是很可怕...... Orz
從評論軟體的角度,只能說,Google 始終展現了「不怕你用」的恢宏氣度。在那個 Hotmail、Yahoo 信箱免費空間大小了不起 50、100MB,GMail 直接給 1GB 的容量、一年後變成 2GB,然後玩起「空間隨著時間慢慢增加」的噱頭,到現在 7.xGB 還在持續增長中。我有點好奇誰能在正常使用下塞滿它......
Google 也不怕你開多個帳號佔據它的資源,不但不怕,還提供了許多功能方便讓你管理眾分身。我是已經很久沒用其他 mail service 了,不知道有哪家有做到如此程度?
從另一個角度來看,Google 的功能大多悄悄無聲無息地出現,像「POP3 下載」這功能,在開放時網路上有喧囂一陣,所以還有點印象。但是這篇提到的其他功能,就根本也不知道啥時候冒出來的,更不用講 GMail 裡頭 LAB 那一卡車的東西了。
不知道這些功能,使用上也沒啥大妨礙;多了這些功能,你也不會覺得被妨礙。
又不免吐槽一下 M$,M$ 常常怕使用者不知道他做了多少改變,問題是改變之後反而不知道要怎麼用了,想回頭用舊的版本還不行(最近才遇到 Windows 2000 安裝 Skype 5.x 版會死翹翹,還好網路上還有 4.x 的免安裝版可以用 [怒]),說明文件又爛得要命,難怪 M$ 連 Office 都可以推證照制度...... Orz
最後說回行銷面,我想這篇就是受到 Google 行銷手法(個人覺得不算行銷,但是人家科班出身的都這樣講了.....)影響下的產物:
是的,除了沒有 Buzz、Chat、Calendar 這些 mail 以外的功能,其餘畫面操作跟 A 帳號登入時一模一樣。A、B 帳號可以同時掛在同一個瀏覽器底下,而且不用知道/輸入 A 帳號的密碼。另外,要同時代管幾個帳號也都不是問題、完全不會混亂。
不過這招有個限制,就是 A、B 兩個帳號的 domain name 必須是一樣的,foo@gmail.com 跟 mail@foo.com 是無法這樣設定的。
心得感想
不管是從哪個角度來看,都是感觸良多。
從軟體開發的角度,只能說自嘆不如。當然,上頭說得這些功能並不需要什麼高深的技術或演算法,問題在於細節很多:得同時兼顧方便性與安全性、還不能造成使用上的混亂與衝突,如果連版本演進的功夫一起算下去,Google 在軟體架構設計上真的是很可怕...... Orz
從評論軟體的角度,只能說,Google 始終展現了「不怕你用」的恢宏氣度。在那個 Hotmail、Yahoo 信箱免費空間大小了不起 50、100MB,GMail 直接給 1GB 的容量、一年後變成 2GB,然後玩起「空間隨著時間慢慢增加」的噱頭,到現在 7.xGB 還在持續增長中。我有點好奇誰能在正常使用下塞滿它......
Google 也不怕你開多個帳號佔據它的資源,不但不怕,還提供了許多功能方便讓你管理眾分身。我是已經很久沒用其他 mail service 了,不知道有哪家有做到如此程度?
從另一個角度來看,Google 的功能大多悄悄無聲無息地出現,像「POP3 下載」這功能,在開放時網路上有喧囂一陣,所以還有點印象。但是這篇提到的其他功能,就根本也不知道啥時候冒出來的,更不用講 GMail 裡頭 LAB 那一卡車的東西了。
不知道這些功能,使用上也沒啥大妨礙;多了這些功能,你也不會覺得被妨礙。
又不免吐槽一下 M$,M$ 常常怕使用者不知道他做了多少改變,問題是改變之後反而不知道要怎麼用了,想回頭用舊的版本還不行(最近才遇到 Windows 2000 安裝 Skype 5.x 版會死翹翹,還好網路上還有 4.x 的免安裝版可以用 [怒]),說明文件又爛得要命,難怪 M$ 連 Office 都可以推證照制度...... Orz
最後說回行銷面,我想這篇就是受到 Google 行銷手法(個人覺得不算行銷,但是人家科班出身的都這樣講了.....)影響下的產物:
- 「這是啥功能...... =="」 or 「最近有一批功能好便宜 [誤]」
- 哇靠!這他 x 的超好用的啦...
- 什麼,你居然不知道? 好好好,我教你......
於是乎,推銷員有了、教育人員有了、甚至連文件撰寫人員也有了(雖然 Google 本身的文件、即使是中文版的也不差)。Google 沒有想一次就改變全世界,甚至可能根本沒有想改變全世界,比較像是「我需要用這個,你要用也歡迎」。但是,世界改變了......
「如何吃下一頭大象?」「一次吃一口」
嗯... 還有很長的路要走...... [遠目]
2011-09-01
粗探 GWT Image 內的實做方式
GWT 當中的 Widget,大概只有 Button 的使用率大於 Image(這也難講,說不定有些人直接用 Image 作 button...... XD)。所以來探究一下 source code 寫了啥東西。
要建立一個 Image,最直接了當的用法是給它 url:
這裡的 url 使用相對路徑亦可,不過得注意是相對於載入這個 GWT module 的頁面就是了。
切到這個 Image(String) 這個 constructor,會發現當中做了兩件事情:
設定 style name 這檔子事情有點無關緊要,忽略不管。至於 state 這個 field 是怎麼一回事?這似乎得要回頭看開頭 JavaDoc 寫的:
於是找到 Image 裡頭 State 這個 private 的 abstract class。它只有兩個 method 不是 abstract 的:onLoad(Image)、fireSyntheticLoadEvent(Image),這兩個都跟 event 有關,在這篇文章當中先略過,以免枝節太多。其餘的 abstract method 留給 ClippedState、UnclippedState 實做。
比對 ClippedState 與 UnclippedState 實做 method 的差異,差別在於 ClippedState 多了 width、height、left、top 這幾個 field,UnclippedState 在取這些值時,是直接對 Image 所屬的 ImageElement 取值,而 ClippedState 則直接回傳 field 的值。另外,如果叫用到 ClippedState.setUrl() 會將 state 切換到 UnclippedState;反之,如果叫用到 UnclippedState.setVisibleRect() 與 setUrlAndVisibleRect() 會將 state 切換到 ClippedState。
這到底在幹什麼?
回歸實際用途,ClippedState 的目的是只顯示圖片上的某個矩形區塊,所以得加上長、寬、起始位置等資訊。製造出這種效果的方法,則是靠 CSS 設定 span 的 background 來辦到。怎麼知道的呢?答案在 constructor 當中的這行:
先用 ClippedImageImpl.createStructure() 製造出一個 Element 物件,然後再把原本 Image 的 element 換成這個。再仔細看一下 ClippedImageImpl 裡頭的寫法,發現它直接用最硬幹的方式設定 element 的 HTML 與 style,也難怪會抽出去自成一個 class。這說明了為甚麼 JavaDoc 強調當 clipped 與 unclipped 互換時,所有的 style 設定都會消失。
重新回到 Image,會發現這個 class 只是邏輯上的存在,為了做到 clipped/unclipped 的效果,所以透過 State 來處理;因為底層實做方式的不同,所以當物件的行為模式轉換時變更到對應的 state。而真正對應 DOM,則是 ImageElement(unclipped mode)與 SpanElement(clipped mode)。使用 Image 時哪會想到底下這麼多怪東西?好的 class 如當是也......
Image 最後還有一個 perfetch(String) 的功能,就留待下回分解了(?)
這篇是退伍後的復健治療... 所以... [遮臉]
要建立一個 Image,最直接了當的用法是給它 url:
Image img = new Image("http://an.url/pic.jpg");這裡的 url 使用相對路徑亦可,不過得注意是相對於載入這個 GWT module 的頁面就是了。
切到這個 Image(String) 這個 constructor,會發現當中做了兩件事情:
- 將 state 設定為新產生的 UnclippedState 物件
- 設定 style name 為 "gwt-Image"
設定 style name 這檔子事情有點無關緊要,忽略不管。至於 state 這個 field 是怎麼一回事?這似乎得要回頭看開頭 JavaDoc 寫的:
「The image can be in 'unclipped' mode (the default) or 'clipped' mode.」也就是說,Image 透過 state 來決定當下是哪一種使用方式,這可以解釋為甚麼有另一個 Image(String, int, int, int, int) 的 constructor。實際去看 Image 的 method 行為,getter、setter、onLoad() 等都是由 state 負責,只有跟 event handler 有關的 method 是用 Widget.addHandler() 處理。
於是找到 Image 裡頭 State 這個 private 的 abstract class。它只有兩個 method 不是 abstract 的:onLoad(Image)、fireSyntheticLoadEvent(Image),這兩個都跟 event 有關,在這篇文章當中先略過,以免枝節太多。其餘的 abstract method 留給 ClippedState、UnclippedState 實做。
比對 ClippedState 與 UnclippedState 實做 method 的差異,差別在於 ClippedState 多了 width、height、left、top 這幾個 field,UnclippedState 在取這些值時,是直接對 Image 所屬的 ImageElement 取值,而 ClippedState 則直接回傳 field 的值。另外,如果叫用到 ClippedState.setUrl() 會將 state 切換到 UnclippedState;反之,如果叫用到 UnclippedState.setVisibleRect() 與 setUrlAndVisibleRect() 會將 state 切換到 ClippedState。
這到底在幹什麼?
回歸實際用途,ClippedState 的目的是只顯示圖片上的某個矩形區塊,所以得加上長、寬、起始位置等資訊。製造出這種效果的方法,則是靠 CSS 設定 span 的 background 來辦到。怎麼知道的呢?答案在 constructor 當中的這行:
image.replaceElement(impl.createStructure(url, left, top, width, height));
先用 ClippedImageImpl.createStructure() 製造出一個 Element 物件,然後再把原本 Image 的 element 換成這個。再仔細看一下 ClippedImageImpl 裡頭的寫法,發現它直接用最硬幹的方式設定 element 的 HTML 與 style,也難怪會抽出去自成一個 class。這說明了為甚麼 JavaDoc 強調當 clipped 與 unclipped 互換時,所有的 style 設定都會消失。
重新回到 Image,會發現這個 class 只是邏輯上的存在,為了做到 clipped/unclipped 的效果,所以透過 State 來處理;因為底層實做方式的不同,所以當物件的行為模式轉換時變更到對應的 state。而真正對應 DOM,則是 ImageElement(unclipped mode)與 SpanElement(clipped mode)。使用 Image 時哪會想到底下這麼多怪東西?好的 class 如當是也......
Image 最後還有一個 perfetch(String) 的功能,就留待下回分解了(?)
這篇是退伍後的復健治療... 所以... [遮臉]
2011-07-04
App Engine 1.5.1 版發佈
原文網址:http://googleappengine.blogspot.com/2011/06/app-engine-151-release.html
Google I/O 已經結束一個月,所以我們覺得應該再來個版本發佈了。這個月我們發佈 ProtoRPC 這個正式的 Python API;讓 SDK 有 HRD(High Replication Datastore)的功能,協助開發者更能理解同步 model;另外增加了 Channel API、以及一些好東西。列舉如下:
service 變更
更新 Java 和 Python 的 API
新的 Python API
Datastore
Google I/O 已經結束一個月,所以我們覺得應該再來個版本發佈了。這個月我們發佈 ProtoRPC 這個正式的 Python API;讓 SDK 有 HRD(High Replication Datastore)的功能,協助開發者更能理解同步 model;另外增加了 Channel API、以及一些好東西。列舉如下:
service 變更
- 地理定位 header:App Engine 現在會在每個 client 的 request 當中夾帶 header,來盡可能地分辨是哪一個國家發出的 request。「X-AppEngine-country」這個 header 可以讓你依照使用者的所在地來客製化內容。我們希望這代表使用者不用再到「你的國家」下拉選單當中選擇。
更新 Java 和 Python 的 API
- Channel API(支援 Presence):現在你可以為你的 application 設定內建的 service,來偵測使用者的 presence。這讓你可以在使用者連線或斷線時作對應的行為。
- Image API(支援 WebP):Image API 現在支援 WebP 格式。WebP 是一種新的圖像格式,Google 在今年初的時候開放原始碼。這個格式是用破壞性壓縮的方式,可以比 JPEG 格式檔案小 39% 、卻提供相同的畫質。
新的 Python API
- ProtoRPC: ProtoRPC 是一個 open source 的 frame,用來建立一個良好定義、易於使用、web base 的 RPC service。雖然 ProtoRPC 跟 Google Protocol Buffers 定義 service 差不多,但 ProtoRPC 的目標是讓開發人員更容易開始定義 web base 的 service,同時允許這些 service 隨著時間改變而能逐步成型與拓展。
Datastore
- SDK 中的 HRD:從發佈 HRD時,我們就希望能提供工具、幫助開發人員在設計 application 時了解和測試新的同步 model。1.5.1 SDK(Java 與 Python 版)可以模擬 HRD 的同步 model。這表示在設定對應的 SDK 選項後,跨 entity group 的查詢結果,偶爾會與剛寫入的資料有出入。這應該會讓你開發的過程中,處理這個同步 model 更加靈活。
(最後一段懶得翻譯 [逃])
2011-07-02
Source Multiplayer Networking [下]
輸入預測
前提假設是:有一個玩家的網路延遲為 150ms,然後開始往前移動。按下 +FORWARD 鍵的訊息儲存在一個 user command 當中,然後送到 server。user command 就會用移動的程式碼處理,玩家的角色也會在遊戲世界當中往前移動。這個遊戲世界狀態的改變,會在下一個 snapshot 更新時送給所有的 client。因此,玩家在開始行走之後 150ms 才會看到移動的變化。這種延遲狀況適用於所有玩家的行為,例如移動、武器射擊等,網路延遲越嚴重、這個狀況就會更嚴重。
玩家之間輸入與對應視覺回饋的延遲,造成一個奇怪且不自然的感覺,使得很難移動或是精準地瞄準。client 端的輸入預測(設定值 cl_predict 1)是消除這種延遲、使玩家感覺動作是即時的一種方法。與其等待 server 更新自己的位置,還不如 client 直接預測自己所下 user command 的結果。因此,server 處理 user command 的程式碼與規則,現在改由 client 端照樣處理。做完預測後,client 端的玩家會馬上移動到新的地點,但對 server 來說,那人仍然在老地方。
150ms 後,client 會收到 server 傳來的 snapshot,當中包含了之前預測 user command 產生的改變。然後 client 比較 server 計算的位置跟自己預測的位置,如果它們的值不相同,就會產生預測錯誤。這表示 client 在處理 user command 時沒有其他 entity 或是環境正確的資訊。client 就必須校正自己的位置,因為 server 有最終決定權可蓋過 client 端的預測值。當 cl_showerror 1 啟動,預測錯誤發生時 client 端就看得到。預測錯誤的校正會相當明顯,client 端看到的畫面也會亂跳。在一個較短的時間當中逐步修正錯誤(設定值:cl_smoothtime),可以較平滑地解決這個問題。平順預測誤差的功能也可以透過設定 cl_smooth 0 來關掉。
只有在 client 端與 server 端都知道同樣的規則以及物體的狀態,才有辦法預測物體的行為。但通常並非如此,因為 server 通常會比 client 知道更多物件資訊。client 只會看到一小部份的遊戲世界、以及僅夠繪製物件的資料量。因此,只能對 client 端自己控制的玩家、武器作預測。在這一點上,正確地預測其他玩家或是物體之間的交互作用,是無法辦到的。
lag 補償
lag 補償系統會保留現在所有玩家過去一秒位置的歷史紀錄(可以用 sv_maxunlag 來設定間隔長度)。如果 user command 被執行到,server 會用下面的公式預測這個 command 是什麼時候執行的:

上頭這畫面是在一個用 net_fakelag 設定 200ms 延遲的 listen server 上擷取下來,此時 server 剛剛確認命中。 紅色 hitbox 顯示 client 在 100ms 之前看到的目標位置。在那之後,目標持續往左移動,直到 user command 到達 server。在 user command 到達後,server 用 command 執行時間作估算,將目標位置還原成藍色 hitbox 的地方。server 計算射擊的軌跡、確認擊中(client 看到噴血的效果)。
client 跟 server 的 hitbox 不會完全相符,這是因為時間測量產生的些微誤差。對於快速移動的物體來說,即使只是幾 ms 的差別,也會導致幾英吋的誤差。多人遊戲中的命中檢測並沒有辦法達到 pixel 層的完全吻合,精準度的限制在於 tickrate 以及物體移動的速度。增加 tickrate 會提昇命中檢測的精準度,但需要更多的 CPU、記憶體、以及 server 與 client 之間的網路頻寬。
講到這裡,有個問題就浮現了:為甚麼 server 上的命中檢測這麼複雜?往回追溯玩家位置與命中確認的精準度誤差,可以在 client 端以 pixel 等級的精準度處理得更輕鬆。client 端只要告訴 server 哪個玩家在哪裡被打中的「擊中」訊息就可以了。不過我們不能容許這種簡化的想法,因為遊戲 server 不能在這類重要的判斷上相信 client。即使 client 很「乾淨」、並有 Valve Anti-Cheat(VAC)的保護,但封包在送到遊戲 server 的途中還是有可能被第三方的機器修改。這些「cheat proxy」可以在網路封包中注入「命中」的訊息而不被 VAC 徵測到(「中間人」式的攻擊法)。
網路延遲與 lag 補償建立出似乎不合真實世界邏輯的悖論。例如,你可能在已經完全隱蔽、無法被看到的情況下被對手擊中。這是因為 server 把你的 hitbox 移動回之前的位置,那時你仍暴露在攻擊者的視野中。一般來說,這種不一致的問題無法解決,因為有相當緩慢的封包。在真實世界中,你不會注意到這個問題,因為光(封包)傳遞的這麼快,你跟你周圍的每個人在當下都看到同一個世界。
網路圖表
Source 引擎提供一些工具來檢查 client 的連線速度與品質。最受歡迎的是網路圖表,可以用 net_graph 2 或 +graph 來啟用。流入的封包以由左至右的移動細線條表示,每一行的高度代表封包的大小。 如果線段之間出現間隙,就表示封包遺失或是不在正確的順序到達。線段以顏色區分它們所包含的資料。
在網路圖表的下方,第一行顯示你目前的 FPS、平均的延遲時間,以及當下的 cl_updaterate 值。第二行顯示最後一個封包(snapshot)的大小(以 Byte 為單位)、平均流入頻寬,以及每秒接收到的封包數。第三行的資料相似,只是資料來源是流出的封包(user command)。

最佳化
預設的網路設定是針對在 Internet 上的專屬主機進行遊戲的設計。這樣的設定在大多數 client/server 端的硬體配備與網路配置能取得平衡點,使之能運作良好。 對於在 Internet 上進行的遊戲,client 端唯一該調的變數是「rate」,它決定了你的網路連線中有多少可用的頻寬(以 byte/sec 為單位)。較佳的設定數據如下:modem 使用者設為 4500、ISDN 使用者設為 6000、DSL 以上的使用者設為 10000。
在高效能的網路環境中,client 與 server 都具備必須的硬體資源,就可以調整平寬與 tickrate 設定,以獲得更好的遊戲精準度。增加 server 的 tickrate 通常會提高移動與射擊的精準度,相對耗費更多的 CPU 運算成本。一個設定 tickrate 為 100 的 CS:S server 會比用預設 tickrate(值為 33)的 server 多 3 倍的 CPU 負荷。這會導致嚴重的計算延遲、尤其是很多人在同一時間射擊時。不建議遊戲 server 的 tickrate 值超過 66,來保留必要的 CPU 資源以備不時之需。
如果 server 用較高的 tickrate 運作,只要所需的頻寬(rate)夠用,client 端可以增加它們的 snapshot 更新頻率(設定值:cl_updaterate)和 command 頻率(設定值:cl_cmdrate)。snapshot 的更新頻率受限於 server 的 tickrate,server 無法在每個 tick 送兩個以上的更新資訊。所以,如果 server 的 tickrate 為 66,client 端的 cl_updaterate 最高為 66。如果你增加 snapshot 的頻率而遇到封包遺失或堵塞,你就必須調降這個數值。在增加 cl_updaterate 的同時,你也可以降低畫面的 interpolation 延遲(cl_interp)。預設的 interpolation 延遲為 0.1 秒,起因於預設的 cl_updaterate 20 這個設定。畫面的 interpolation 延遲讓移動的玩家比固定不動的玩家多了些微的優勢,因為移動的玩家可以早一點點看到他的目標。這種影響無法避免,但卻可以透過調降畫面 interpolation 延遲來減低影響。如果兩個玩家都在移動,則畫面延遲同時影響雙方,沒有人有這類優勢。
snapshot rate 與畫面 interpolation 延遲的關係如下:
Source Engine v7 (CSS - HL2DM)
Source Engine v14/v15 / Orange Box Engine (TF2 - DoD S) + Left 4 Dead Engine
小技巧
前提假設是:有一個玩家的網路延遲為 150ms,然後開始往前移動。按下 +FORWARD 鍵的訊息儲存在一個 user command 當中,然後送到 server。user command 就會用移動的程式碼處理,玩家的角色也會在遊戲世界當中往前移動。這個遊戲世界狀態的改變,會在下一個 snapshot 更新時送給所有的 client。因此,玩家在開始行走之後 150ms 才會看到移動的變化。這種延遲狀況適用於所有玩家的行為,例如移動、武器射擊等,網路延遲越嚴重、這個狀況就會更嚴重。
玩家之間輸入與對應視覺回饋的延遲,造成一個奇怪且不自然的感覺,使得很難移動或是精準地瞄準。client 端的輸入預測(設定值 cl_predict 1)是消除這種延遲、使玩家感覺動作是即時的一種方法。與其等待 server 更新自己的位置,還不如 client 直接預測自己所下 user command 的結果。因此,server 處理 user command 的程式碼與規則,現在改由 client 端照樣處理。做完預測後,client 端的玩家會馬上移動到新的地點,但對 server 來說,那人仍然在老地方。
150ms 後,client 會收到 server 傳來的 snapshot,當中包含了之前預測 user command 產生的改變。然後 client 比較 server 計算的位置跟自己預測的位置,如果它們的值不相同,就會產生預測錯誤。這表示 client 在處理 user command 時沒有其他 entity 或是環境正確的資訊。client 就必須校正自己的位置,因為 server 有最終決定權可蓋過 client 端的預測值。當 cl_showerror 1 啟動,預測錯誤發生時 client 端就看得到。預測錯誤的校正會相當明顯,client 端看到的畫面也會亂跳。在一個較短的時間當中逐步修正錯誤(設定值:cl_smoothtime),可以較平滑地解決這個問題。平順預測誤差的功能也可以透過設定 cl_smooth 0 來關掉。
只有在 client 端與 server 端都知道同樣的規則以及物體的狀態,才有辦法預測物體的行為。但通常並非如此,因為 server 通常會比 client 知道更多物件資訊。client 只會看到一小部份的遊戲世界、以及僅夠繪製物件的資料量。因此,只能對 client 端自己控制的玩家、武器作預測。在這一點上,正確地預測其他玩家或是物體之間的交互作用,是無法辦到的。
lag 補償
在 Source 的 SDK 中可以看到 lag 補償與 view interpolation 的所有原始碼
假設一個玩家在 client 端時間 10.5 的時候開槍打一個目標。開槍的訊息會裝在一個 user command 當中,然後送到 server 去。當這個封包在網路上傳輸時,server 持續運作遊戲世界,所以目標可能移到不同的位置。這個 user command 在 server 時間 10.6 的時候到達,但即使玩家已經確實瞄準這個目標,server 還是可能會判定沒有命中。可以藉由 server 端的 lag 補償(設定值:sv_unlag 1)來校正這個誤差。lag 補償系統會保留現在所有玩家過去一秒位置的歷史紀錄(可以用 sv_maxunlag 來設定間隔長度)。如果 user command 被執行到,server 會用下面的公式預測這個 command 是什麼時候執行的:
command 執行時間 = server 目前時間 - 封包往來時間 - client 端 interpolation然後 server 會把所有玩家——也僅限玩家——移回 command 執行時的位置。這樣 user command 執行時,命中偵測就會正確。而在 user command 執行完後,玩家就會恢復到原來應該在的位置。
注意:因為算式中包含 entity interpolation,所以拿掉 entity interpolation 可能會導致預期外的結果。在 listen server 上,你可以設定 sv_showimpacts 1 來看到 server 與 client 不同 hitbox:

上頭這畫面是在一個用 net_fakelag 設定 200ms 延遲的 listen server 上擷取下來,此時 server 剛剛確認命中。 紅色 hitbox 顯示 client 在 100ms 之前看到的目標位置。在那之後,目標持續往左移動,直到 user command 到達 server。在 user command 到達後,server 用 command 執行時間作估算,將目標位置還原成藍色 hitbox 的地方。server 計算射擊的軌跡、確認擊中(client 看到噴血的效果)。
client 跟 server 的 hitbox 不會完全相符,這是因為時間測量產生的些微誤差。對於快速移動的物體來說,即使只是幾 ms 的差別,也會導致幾英吋的誤差。多人遊戲中的命中檢測並沒有辦法達到 pixel 層的完全吻合,精準度的限制在於 tickrate 以及物體移動的速度。增加 tickrate 會提昇命中檢測的精準度,但需要更多的 CPU、記憶體、以及 server 與 client 之間的網路頻寬。
講到這裡,有個問題就浮現了:為甚麼 server 上的命中檢測這麼複雜?往回追溯玩家位置與命中確認的精準度誤差,可以在 client 端以 pixel 等級的精準度處理得更輕鬆。client 端只要告訴 server 哪個玩家在哪裡被打中的「擊中」訊息就可以了。不過我們不能容許這種簡化的想法,因為遊戲 server 不能在這類重要的判斷上相信 client。即使 client 很「乾淨」、並有 Valve Anti-Cheat(VAC)的保護,但封包在送到遊戲 server 的途中還是有可能被第三方的機器修改。這些「cheat proxy」可以在網路封包中注入「命中」的訊息而不被 VAC 徵測到(「中間人」式的攻擊法)。
網路延遲與 lag 補償建立出似乎不合真實世界邏輯的悖論。例如,你可能在已經完全隱蔽、無法被看到的情況下被對手擊中。這是因為 server 把你的 hitbox 移動回之前的位置,那時你仍暴露在攻擊者的視野中。一般來說,這種不一致的問題無法解決,因為有相當緩慢的封包。在真實世界中,你不會注意到這個問題,因為光(封包)傳遞的這麼快,你跟你周圍的每個人在當下都看到同一個世界。
網路圖表
Source 引擎提供一些工具來檢查 client 的連線速度與品質。最受歡迎的是網路圖表,可以用 net_graph 2 或 +graph 來啟用。流入的封包以由左至右的移動細線條表示,每一行的高度代表封包的大小。 如果線段之間出現間隙,就表示封包遺失或是不在正確的順序到達。線段以顏色區分它們所包含的資料。
在網路圖表的下方,第一行顯示你目前的 FPS、平均的延遲時間,以及當下的 cl_updaterate 值。第二行顯示最後一個封包(snapshot)的大小(以 Byte 為單位)、平均流入頻寬,以及每秒接收到的封包數。第三行的資料相似,只是資料來源是流出的封包(user command)。
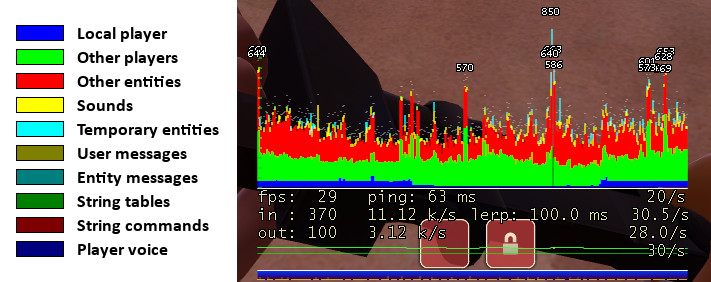
最佳化
預設的網路設定是針對在 Internet 上的專屬主機進行遊戲的設計。這樣的設定在大多數 client/server 端的硬體配備與網路配置能取得平衡點,使之能運作良好。 對於在 Internet 上進行的遊戲,client 端唯一該調的變數是「rate」,它決定了你的網路連線中有多少可用的頻寬(以 byte/sec 為單位)。較佳的設定數據如下:modem 使用者設為 4500、ISDN 使用者設為 6000、DSL 以上的使用者設為 10000。
在高效能的網路環境中,client 與 server 都具備必須的硬體資源,就可以調整平寬與 tickrate 設定,以獲得更好的遊戲精準度。增加 server 的 tickrate 通常會提高移動與射擊的精準度,相對耗費更多的 CPU 運算成本。一個設定 tickrate 為 100 的 CS:S server 會比用預設 tickrate(值為 33)的 server 多 3 倍的 CPU 負荷。這會導致嚴重的計算延遲、尤其是很多人在同一時間射擊時。不建議遊戲 server 的 tickrate 值超過 66,來保留必要的 CPU 資源以備不時之需。
如果 server 用較高的 tickrate 運作,只要所需的頻寬(rate)夠用,client 端可以增加它們的 snapshot 更新頻率(設定值:cl_updaterate)和 command 頻率(設定值:cl_cmdrate)。snapshot 的更新頻率受限於 server 的 tickrate,server 無法在每個 tick 送兩個以上的更新資訊。所以,如果 server 的 tickrate 為 66,client 端的 cl_updaterate 最高為 66。如果你增加 snapshot 的頻率而遇到封包遺失或堵塞,你就必須調降這個數值。在增加 cl_updaterate 的同時,你也可以降低畫面的 interpolation 延遲(cl_interp)。預設的 interpolation 延遲為 0.1 秒,起因於預設的 cl_updaterate 20 這個設定。畫面的 interpolation 延遲讓移動的玩家比固定不動的玩家多了些微的優勢,因為移動的玩家可以早一點點看到他的目標。這種影響無法避免,但卻可以透過調降畫面 interpolation 延遲來減低影響。如果兩個玩家都在移動,則畫面延遲同時影響雙方,沒有人有這類優勢。
snapshot rate 與畫面 interpolation 延遲的關係如下:
Source Engine v7 (CSS - HL2DM)
畫面 interpolation 延遲 = cl_interp_ratio / cl_updaterate舉例來說,如果 client 端每秒收到 66 個更新資訊,interpolation 的比率是 2,那麼畫面 interpolation 延遲會是 0.03 秒。這樣畫面 interpolation 延遲就從 100ms 掉到 30ms。cl_interp 在 Source Engine v7 當中被停用,你需要使用 cl_interp_ration 與 cl_updaterate 來設定畫面 interpolation 延遲。把 cl_interpolation 設為 0 來完全移除畫面 interpolation 延遲會無法運作,且造成跳 tone 的動畫效果,命中偵測也會很糟。
Source Engine v14/v15 / Orange Box Engine (TF2 - DoD S) + Left 4 Dead Engine
cl_interp = cl_interp_ratio / cl_updaterate舉例來說,如果 client 端每秒收到 66 個更新資訊、interpolation 的比例是 2,你可以把 cl_interp 設為 0.03。這樣你的畫面 interpolation 延遲就從 100ms 降低到 30ms。在這個例子中,cl_interp_ratio 是用來「限制」cl_interp 的值。在 Oragne Box 引擎中,你無法關掉畫面 interpolation 延遲。
小技巧
- 除非你完全知道你在幹麼,不然不要更改 console 的設定。
- 如果 server 或網路負荷不了的話,大多「高效率」的設定會導致徹底的反效果。
- 不要關閉畫面 interpolation 和 lag 補償。
- 這樣作不會提昇移動或射擊的精準度。
- 對某個 client 而言的最佳化設定,可能無法適用於其他 client。
- 在還沒有在你的系統上驗證之前,不要用其他 client 的設定。
- 如果你在遊戲或 SourceTV 中用「第一人稱」觀看某個玩家,你看到的不完全是玩家看到的畫面。
- 觀眾看到的遊戲世界是沒有 lag 補償的畫面。
2011-06-05
Source Multiplayer Networking [上]
原文網址:http://developer.valvesoftware.com/wiki/Source_Multiplayer_Networking
備註:下列譯文可能已經與原文網址所載有所差異,偏偏我也忘記是哪時候開始抓這篇下來翻譯的了...... 囧>
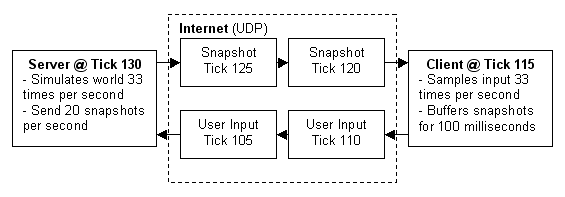
底層使用 Source Engine 的多人遊戲是使用 Client-Server 的網路架構。通常 server 是在一個專用的主機上運作,負責模擬出遊戲中的世界、掌控遊戲規則、以及處理玩家輸入。client 則是玩家的電腦,會連上遊戲 server。client 跟 server 之間的通訊模式是以高頻(每秒 20~30 個)傳送小資料量封包。client 接收 server 端傳來當下遊戲狀態的資料然後產生影音,都是靠這些微小的資料更新。client 也會對輸入裝置(鍵盤、滑鼠、麥克風等)作取樣,然後把這些輸入的取樣數據傳回 server 以作進一步處理。client 只跟遊戲 server 作資料傳輸,而不是像 p2p 應用程式那樣互相傳輸。跟單人遊戲不同,多人遊戲必須處理各種封包傳輸所產生的新問題。
網路頻寬是有限的,所以 server 不能在遊戲中世界有所改變時,就送一個新的變更封包給所有 client。取而代之的方法是,server 將現在遊戲世界的狀態以固定頻率擷取 snapshot,然後將這些 snapshot broadcast 給所有 client。client 跟 server 之間的封包傳遞一定會花掉一些時間(例如 ping 所得的時間)。這表示 client 的時間永遠會比 server 的時間晚上一點點。再者,client 端輸入裝置的資料封包在回傳 server 時也會有延遲的狀況,所以 server 正在處理的使用者指令已經是一段時間前所發出的。更麻煩的是,每個 client 的 framerate 跟其他背景程式產生的流量,會導致不同的網路延遲量。網路延遲越嚴重,server 跟 client 之間時間差造成的邏輯問題也會越嚴重。在節奏快速的動作遊戲中,即使是幾個 ms 的延遲,也會讓遊戲有 lag 的感覺;這會讓你很難 K 到其他玩家、或是對移動中的物體作動作。除了網路頻寬限制跟網路延遲外,封包遺失也會造成遊戲的資訊遺失。

為了對付上述這些議題,Source Engine 使用許多技術來解決、或是讓玩家感覺不到這些問題。這些技術包括資料壓縮、interpolation、預測、lag 補償。這些技術細節環環相扣,在某個系統做的改變可能會影響另一個系統。本文會描述這個系統的功能、以及它們如何一同運作。
網絡基礎
server 是以連續不斷、稱為 tick 的時間間隔來模擬出遊戲時間。在預設狀況下會以 66 tick/sec 運作,但 MOD 可以指定它們自己的 tickrate。以 CS(Counter-Strike)為例,Source 使用 33 tick/sec 這種較低的 tickrate 來降低 server 的 CPU 負荷。在每個 tick 的時間裡,server 處理使用者輸入的指令、執行一個物理模擬步驟、檢查遊戲規則、並且更新所有物件的狀態。經過一個 tick 的運算後,server 會依照需要,將遊戲中的世界現況作一個 snapshot、並傳送給需要的 client 端。較高的 tickrate 會增加模擬的精準度,但無論 server 還是 client 也都需要更強力的 CPU 以及更大的頻寬來配合。server 的管理者可以在 command line 下 -tickrate 指令來覆蓋預設的 tickrate。但是 tickrate 改變可能會讓 MOD 無法於預期般運作,所以不建議這樣作。
client 通常只有有限的頻寬。在最糟糕的情況下——用 modem 的玩家——網路速度沒辦法超過 5~7 KB/sec。如果 server 試圖以更快的更新速度傳送資料給 client,必然會發生封包遺失的狀況。因此,client 必須用設定 rate 參數來告訴 server 本身的網路頻寬(單位為 bytes/sec)。這對 client 而言是最重要的網路相關參數,設定正確才能有理想的遊戲體驗。client 可以改變 cl_updaterate 來確保 snapshot 的頻率(預設值為 20),但是 server 的更新速度並不會因此高於 tick 的設定值、或是超過 client 的 rate 限制。server 的管理者可以用 sv_minrate 和 sv_maxrate 限制 client 要求的資料頻率(單位為 byte/sec)。snapshot 的頻率也可以用 sv_minupdaterate 和 sv_maxupdaterate 來設定上下限(單位為 snapshot/sec)。
client 以 server 的 tick 頻率從輸入設備取樣、製造出 user command。user command 基本上是當下鍵盤與滑鼠狀態的一個 snapshot。但並不是每一個 user command 都會送封包到 server,而是以一個固定的頻率(通常是 30/sec)送出這些 command 封包。這意味著兩個或兩個以上的 command 是裝在同一個封包內送出去。client 可以用 cl_cmdrate 增加送出 command 的頻率。這會加強操作回應的靈敏度,但也需要更多的頻寬。
遊戲的數據使用 delta compression 來壓縮,以減輕網路負荷量。這表示 server 不會送出整個世界的 snapshot,而是最後一次已確認變更之後的改變(delta snapshot)。每一個 server 跟 client 之間傳遞的封包都會附加 ack 數字來保持追蹤這些資料串流。通常完整(非 delta)的 snapshot 只有在遊戲開始、或是 client 遺失長達數秒的封包時才會傳送。client 可以用 cl_fullupdate 來要求完整的 snapshot。
系統回應的靈敏度、或著說「使用者輸入」到「遊戲世界做出明顯回應」的時間,取決於很多因素,包括 server/client 的 CPU 負荷量、模擬的 tickrate、資料擷取的頻率、以及 snapshot 更新速度,不過主要因素還是卡在網路封包傳遞的時間。client 送出使用者的指令→server 做出回應→client 接收到 server 的反應,這段時間稱為 latency 或是 ping(或往返時間)。低 latency 在玩多人的線上遊戲是一個很大的優勢。像「預測」以及「lag 補償」等技術,試著把這個優勢壓到最低,使網路速度比較慢的玩家也能跟其他玩家公平競爭。當有足夠的頻寬跟夠力的 CPU,調整網路設定可以讓你得到比較好的遊戲體驗。我們建議保持預設值,因為不適當的改變可能弊多於利。
Entity interpolation
在預設情況下,cleint 每秒會收到 20 個 snapshot。如果遊戲世界中的物體只在 server 傳回的位置顯示,則移動的物體跟動畫看起來會很跳 tone。遺失的封包也會導致明顯的問題。解決這個問題的技巧是回到過去的遊戲時間來繪製,程式會從最後兩個接收到的 snapshot 來 interpolate 出連續性的位置與動畫。 這種技術稱為 client 端的 entity interpolation,預設值是(cl_interpolate 1)為啟動狀態。以每秒 20 個 snapshot 來計算,大概 50ms 就會收到一份更新資料。如果把 client 端的繪製時間回溯 50ms,那麼就可以用最後收到的兩個 snapshot 來作 interpolate。Source Engine 延遲(回溯)100ms 來計算 entity interpolate (設定為 cl_interp 0.1)。這樣作的話,即使少了一個 snapshot,也還是有兩個有效的 snapshot 可以作 interpolate。下圖是 snapshot 到達的時間軸:

client 最後接收到 snapshot 的時間是 10:30(第 344 個 tick)。clinet 的時間以這個 snapshot 及 client 的 frame 頻率持續地增加。如果要繪製一個新畫面的 frame,則描繪的時間點會是當下的時間 10.32 減去 0.1 秒的 interpolate 延遲時間,在這個例子當中就是 10.22。所有的 entity 跟動畫會依比例從 340 與 342 個 tick 中計算 interpolation。
由於我們設定 100ms 的 interpolation 延遲,所以即使 342 的 snapshot 因為封包遺失的關係而沒有收到,interpolation 還是可以透過 340 跟 344 計算得出來。如果超過一個 snapshot 遺失,interpolation 就因為歷史緩衝區的 snapshot 用完而無法運作。在這種情況下就會以目前已知的 snapshot,用簡單的線性 extrapolation(設定值:cl_extrapolate 1)來計算。extrapolation 只能在 0.25 秒內的封包遺失才能運作(設定為 cl_extrapolate_amount),如果超出這個範圍就會產生預測上的誤差。
interpolation 會導致畫面固定「lag」了 100ms,即使你就在 listen server(server 跟 client 在同一台電腦)上頭玩遊戲。所以,如果你開啟 sv_showhitboxes,會用 server 的時間來顯示玩家的 hitbox,這表示它們會比玩家 model 的時間往前了 100ms。這不代表你必須在瞄準其他玩家時,因為 client 的 interpolation 導致 server 端做 lag 補償,而必須校正這個誤差。如果你在 listen server 上關掉 interpolation(設定值為 cl_interpolate 0 以及 cl_lagcompensation 0),hitbox 顯示的值就會跟玩家的 model 相符,但是動畫跟物體移動會變得緊張兮兮的。
備註:下列譯文可能已經與原文網址所載有所差異,偏偏我也忘記是哪時候開始抓這篇下來翻譯的了...... 囧>
底層使用 Source Engine 的多人遊戲是使用 Client-Server 的網路架構。通常 server 是在一個專用的主機上運作,負責模擬出遊戲中的世界、掌控遊戲規則、以及處理玩家輸入。client 則是玩家的電腦,會連上遊戲 server。client 跟 server 之間的通訊模式是以高頻(每秒 20~30 個)傳送小資料量封包。client 接收 server 端傳來當下遊戲狀態的資料然後產生影音,都是靠這些微小的資料更新。client 也會對輸入裝置(鍵盤、滑鼠、麥克風等)作取樣,然後把這些輸入的取樣數據傳回 server 以作進一步處理。client 只跟遊戲 server 作資料傳輸,而不是像 p2p 應用程式那樣互相傳輸。跟單人遊戲不同,多人遊戲必須處理各種封包傳輸所產生的新問題。
網路頻寬是有限的,所以 server 不能在遊戲中世界有所改變時,就送一個新的變更封包給所有 client。取而代之的方法是,server 將現在遊戲世界的狀態以固定頻率擷取 snapshot,然後將這些 snapshot broadcast 給所有 client。client 跟 server 之間的封包傳遞一定會花掉一些時間(例如 ping 所得的時間)。這表示 client 的時間永遠會比 server 的時間晚上一點點。再者,client 端輸入裝置的資料封包在回傳 server 時也會有延遲的狀況,所以 server 正在處理的使用者指令已經是一段時間前所發出的。更麻煩的是,每個 client 的 framerate 跟其他背景程式產生的流量,會導致不同的網路延遲量。網路延遲越嚴重,server 跟 client 之間時間差造成的邏輯問題也會越嚴重。在節奏快速的動作遊戲中,即使是幾個 ms 的延遲,也會讓遊戲有 lag 的感覺;這會讓你很難 K 到其他玩家、或是對移動中的物體作動作。除了網路頻寬限制跟網路延遲外,封包遺失也會造成遊戲的資訊遺失。
為了對付上述這些議題,Source Engine 使用許多技術來解決、或是讓玩家感覺不到這些問題。這些技術包括資料壓縮、interpolation、預測、lag 補償。這些技術細節環環相扣,在某個系統做的改變可能會影響另一個系統。本文會描述這個系統的功能、以及它們如何一同運作。
網絡基礎
server 是以連續不斷、稱為 tick 的時間間隔來模擬出遊戲時間。在預設狀況下會以 66 tick/sec 運作,但 MOD 可以指定它們自己的 tickrate。以 CS(Counter-Strike)為例,Source 使用 33 tick/sec 這種較低的 tickrate 來降低 server 的 CPU 負荷。在每個 tick 的時間裡,server 處理使用者輸入的指令、執行一個物理模擬步驟、檢查遊戲規則、並且更新所有物件的狀態。經過一個 tick 的運算後,server 會依照需要,將遊戲中的世界現況作一個 snapshot、並傳送給需要的 client 端。較高的 tickrate 會增加模擬的精準度,但無論 server 還是 client 也都需要更強力的 CPU 以及更大的頻寬來配合。server 的管理者可以在 command line 下 -tickrate 指令來覆蓋預設的 tickrate。但是 tickrate 改變可能會讓 MOD 無法於預期般運作,所以不建議這樣作。
client 通常只有有限的頻寬。在最糟糕的情況下——用 modem 的玩家——網路速度沒辦法超過 5~7 KB/sec。如果 server 試圖以更快的更新速度傳送資料給 client,必然會發生封包遺失的狀況。因此,client 必須用設定 rate 參數來告訴 server 本身的網路頻寬(單位為 bytes/sec)。這對 client 而言是最重要的網路相關參數,設定正確才能有理想的遊戲體驗。client 可以改變 cl_updaterate 來確保 snapshot 的頻率(預設值為 20),但是 server 的更新速度並不會因此高於 tick 的設定值、或是超過 client 的 rate 限制。server 的管理者可以用 sv_minrate 和 sv_maxrate 限制 client 要求的資料頻率(單位為 byte/sec)。snapshot 的頻率也可以用 sv_minupdaterate 和 sv_maxupdaterate 來設定上下限(單位為 snapshot/sec)。
client 以 server 的 tick 頻率從輸入設備取樣、製造出 user command。user command 基本上是當下鍵盤與滑鼠狀態的一個 snapshot。但並不是每一個 user command 都會送封包到 server,而是以一個固定的頻率(通常是 30/sec)送出這些 command 封包。這意味著兩個或兩個以上的 command 是裝在同一個封包內送出去。client 可以用 cl_cmdrate 增加送出 command 的頻率。這會加強操作回應的靈敏度,但也需要更多的頻寬。
遊戲的數據使用 delta compression 來壓縮,以減輕網路負荷量。這表示 server 不會送出整個世界的 snapshot,而是最後一次已確認變更之後的改變(delta snapshot)。每一個 server 跟 client 之間傳遞的封包都會附加 ack 數字來保持追蹤這些資料串流。通常完整(非 delta)的 snapshot 只有在遊戲開始、或是 client 遺失長達數秒的封包時才會傳送。client 可以用 cl_fullupdate 來要求完整的 snapshot。
系統回應的靈敏度、或著說「使用者輸入」到「遊戲世界做出明顯回應」的時間,取決於很多因素,包括 server/client 的 CPU 負荷量、模擬的 tickrate、資料擷取的頻率、以及 snapshot 更新速度,不過主要因素還是卡在網路封包傳遞的時間。client 送出使用者的指令→server 做出回應→client 接收到 server 的反應,這段時間稱為 latency 或是 ping(或往返時間)。低 latency 在玩多人的線上遊戲是一個很大的優勢。像「預測」以及「lag 補償」等技術,試著把這個優勢壓到最低,使網路速度比較慢的玩家也能跟其他玩家公平競爭。當有足夠的頻寬跟夠力的 CPU,調整網路設定可以讓你得到比較好的遊戲體驗。我們建議保持預設值,因為不適當的改變可能弊多於利。
Entity interpolation
在預設情況下,cleint 每秒會收到 20 個 snapshot。如果遊戲世界中的物體只在 server 傳回的位置顯示,則移動的物體跟動畫看起來會很跳 tone。遺失的封包也會導致明顯的問題。解決這個問題的技巧是回到過去的遊戲時間來繪製,程式會從最後兩個接收到的 snapshot 來 interpolate 出連續性的位置與動畫。 這種技術稱為 client 端的 entity interpolation,預設值是(cl_interpolate 1)為啟動狀態。以每秒 20 個 snapshot 來計算,大概 50ms 就會收到一份更新資料。如果把 client 端的繪製時間回溯 50ms,那麼就可以用最後收到的兩個 snapshot 來作 interpolate。Source Engine 延遲(回溯)100ms 來計算 entity interpolate (設定為 cl_interp 0.1)。這樣作的話,即使少了一個 snapshot,也還是有兩個有效的 snapshot 可以作 interpolate。下圖是 snapshot 到達的時間軸:
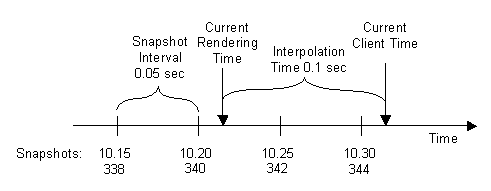
client 最後接收到 snapshot 的時間是 10:30(第 344 個 tick)。clinet 的時間以這個 snapshot 及 client 的 frame 頻率持續地增加。如果要繪製一個新畫面的 frame,則描繪的時間點會是當下的時間 10.32 減去 0.1 秒的 interpolate 延遲時間,在這個例子當中就是 10.22。所有的 entity 跟動畫會依比例從 340 與 342 個 tick 中計算 interpolation。
由於我們設定 100ms 的 interpolation 延遲,所以即使 342 的 snapshot 因為封包遺失的關係而沒有收到,interpolation 還是可以透過 340 跟 344 計算得出來。如果超過一個 snapshot 遺失,interpolation 就因為歷史緩衝區的 snapshot 用完而無法運作。在這種情況下就會以目前已知的 snapshot,用簡單的線性 extrapolation(設定值:cl_extrapolate 1)來計算。extrapolation 只能在 0.25 秒內的封包遺失才能運作(設定為 cl_extrapolate_amount),如果超出這個範圍就會產生預測上的誤差。
interpolation 會導致畫面固定「lag」了 100ms,即使你就在 listen server(server 跟 client 在同一台電腦)上頭玩遊戲。所以,如果你開啟 sv_showhitboxes,會用 server 的時間來顯示玩家的 hitbox,這表示它們會比玩家 model 的時間往前了 100ms。這不代表你必須在瞄準其他玩家時,因為 client 的 interpolation 導致 server 端做 lag 補償,而必須校正這個誤差。如果你在 listen server 上關掉 interpolation(設定值為 cl_interpolate 0 以及 cl_lagcompensation 0),hitbox 顯示的值就會跟玩家的 model 相符,但是動畫跟物體移動會變得緊張兮兮的。
警告:如果在同一時間中關閉 lag 補償( 設定值:cl_lagcompensation 0 )卻開啟 interpolation,會導致預期外的結果。
2011-05-16
App Engine 1.5.0 版發佈
原文網址:http://googleappengine.blogspot.com/2011/05/app-engine-150-release.html
App Engine 團隊一直在拼命準備 Google I/O,而今天我們很高興地宣佈 App Engine 1.5.0——夾帶著一堆完成的新功能——正式發佈了。這個版本帶來了全新的特性:引入了 Backend、Task Queue 的重大改進、全新實驗性質的 Go 語言運行環境、High Replication Datastore 變成預設的設定(價格也降低了!),以及許多調整與 bug 修復。
service 變更
Datastore
API 改變
Administration
Go
這個版本中還有其他一海票的更改、bug 修復,所以請查閱完整的版本更新紀錄,包含所有 Java 與 Python 的議題修正。最後,如果你有興趣知道接下來這一年當中 App Engine 的方向,請到 2011 Google I/O 的其他公告看看!
App Engine 團隊一直在拼命準備 Google I/O,而今天我們很高興地宣佈 App Engine 1.5.0——夾帶著一堆完成的新功能——正式發佈了。這個版本帶來了全新的特性:引入了 Backend、Task Queue 的重大改進、全新實驗性質的 Go 語言運行環境、High Replication Datastore 變成預設的設定(價格也降低了!),以及許多調整與 bug 修復。
service 變更
- Backend:截至目前為止,App Engine application 是在一個短暫存在、動態的 instance 上頭運作,我們啟動它來回應 request 然後再關掉它。這對於建構可擴增的 web application 是很棒的事,但是如果你在找尋建立大型、長時間存活、以及/或密集存取記憶體的底層功能,就會有很多限制。在 1.5.0 版,我們引入了 Backend,讓使用者可以打破這樣的限制!Backend 是由開發人員控制、長時間運行、可定址的 instance 集合,至於需要多少 instance 則任由開發人員設定。這些 instance 沒有 request deadline,它們可以被啟動和停止(或是當呼叫到時動態啟動),它們可以使用 128M~1G 的記憶體、以及一定比例的 CPU。如果你想要了解更多,可以讀一下 Java 與 Python 版的 Backend 文件。
- Pull Queue:現在大多數的用戶在他們的 application 中大量使用 Task Queue,不過在靈活度上還是有很許多改善空間。在 1.5.0 引入的 Pull Queue 讓開發者可以在 application 準備好時,把 task 從 queue 中「pull」出來執行,而不用倚賴 Task Queue 在先前設定好的頻率把 task push 進 queue 中。這表示你可以寫一個 Backend 來作一些背景程序,然後當 Backend 準備好時從 Pull Queue 中 pull 一個或上百個 task 來處理。此外,我們導入了 REST API,它允許外部 service 做同樣的事情。舉例來說,如果你有一個外部 server 是在做圖形轉換或 OCR,你可以用 REST API 來 pull、執行這些 task,然後回傳結果。結合這兩個改進,我們還增加了 payload 的限制與處理速度。我們很高興能同時擴展 Task Queue 的使用、以及加強改善 App Engine 與 REST of the Cloud 之間的整合。
Datastore
- 預設為 High Replication Datastore:High Replication Datastore 經過幾個月的使用和回饋意見(以及至今 99.999% 的正常運作時間),讓我們有信心認為,這對廣大的使用者而言是正確的方向。所以,今天我們做了兩件事:當新的 application 建立時預設使用 HRD;降低 HRD 儲存的價格,從 $0.45 降低到 $0.24,來鼓勵大家開始計畫轉移至 HRD。我們一直很感謝早先使用 HRD 的使用者,他們測試、發現問題,並在這個版本當中修復其中的一些問題。
API 改變
- 為了回應眾人的期盼,HTTP request 跟 response 的大小增加至 32MB。
- Mail API:我們對 Mail API 增添一些限制,好讓所有使用這個 service 的 application 提高可靠性和信任度。首先,電子郵件必須以 Google 管理的電子郵件帳號(Gmail 或是 Google Apps 均可)寄出。其次,對新建立的 application,每天免費的額度從 2000 減少到 100。這些都將有助於確保 application 發出的信件可以可靠地到達目的地。
Administration
- 下載程式碼:1.5.0 當中,除了上傳程式碼的使用者可以下載原始碼之外,也讓列在 Admin Console 的 project owner 可以下載。owner 是在 1.4.2 版引入,是一種 admin 角色。
Go
- 新的運作環境:在 1.5.0 版當中,我們啟用一個實驗性質、給 Go 程式語言使用的運作環境。Go 是一個開放程式碼、靜態類別、編譯型的語言,但有動態、輕量級的感覺。這對 App Engine 來說也是有趣的新選擇,因為 Go 會 compile 成 native 碼;對 CPU 密集使用的 task 來說,用 Go 會是一個好選擇。截至目前為止,Go 版的 App Engine SDK 已經可供下載了,我們將儘快讓你可以 deploy Go 的 application 到 App Engine 上。如果你有興趣早一點開始「Go」,註冊就可以成為正式啟用時的首批測試者。閱讀 Go Blog 的公告,當中有更多細節。
這個版本中還有其他一海票的更改、bug 修復,所以請查閱完整的版本更新紀錄,包含所有 Java 與 Python 的議題修正。最後,如果你有興趣知道接下來這一年當中 App Engine 的方向,請到 2011 Google I/O 的其他公告看看!
2011-04-25
使用 Google Plugin for Eclipse 的十大理由
原文網址:http://googlewebtoolkit.blogspot.com/2011/03/top-ten-reasons-to-use-google-plugin.html
就像我再 JUGs 以及世界各地的研討會說的,我常常訝異於有些人從來沒有見識過 Google Plugin for Eclipse 當中的優秀功能,例如在 GWT application 當中使用 Eclipse debugger。所以呢,這裡沒有特別排序地列舉了十個你應該用 Google Plugin for Eclipse (GPE)的理由。
還沒試過這些東西嗎?馬上就安裝 GPE 吧!
就像我再 JUGs 以及世界各地的研討會說的,我常常訝異於有些人從來沒有見識過 Google Plugin for Eclipse 當中的優秀功能,例如在 GWT application 當中使用 Eclipse debugger。所以呢,這裡沒有特別排序地列舉了十個你應該用 Google Plugin for Eclipse (GPE)的理由。
- GWT+GAE 變得簡單。GPE 是開始使用 GWT 與 Google App Engine(GAE) 最簡單的方法。只要在 Eclipse update site 安裝 plugin 時勾選 SDK 就可以了。 用這個方法升級 SDK(Help→Check for updates)也很容易,當有新版本時 Eclipse 的狀態列也會提示你。
- Wizards。建立生平第一個 GWT+GAE 的 project 十分簡單。按下 File→New→Web application project,然後一個範例 application 就出現了,你可以在本機端踹看看有沒有問題,然後 deploy 到 GAE 上頭去。除了建立一個新的 project,還有建立 UiBinder template、ClientBundles、GWT module 以及 entry point 的 wizard。要使用這些 wizard,按下 File→New,然後找到 GWT 標誌底下的項目(或是按下 File→New→Other,然後瀏覽 Google Web Toolkit 的目錄)。
- GWT Designer,現在整合到 GPE 中,讓你快速地建立一個 GUI。要看它的運作狀況,先建立一個 extends GWT Composite 的 class,然後在檔案上頭按下右鍵→Open With→GWT Designer。當編輯器開啟後,按下底端 Design 這個 tab。當 GWT Designer 啟動後,在工具區點選一個工具(例如 LayoutPanel),然後在設計視窗的空白處按一下,好讓 widget 放到你指定的地方。按下 Source 的 tab 可以看到 GWT Designer 幫你寫的程式碼。這是學習新的 cell widget(像 CellTable 跟 TextColumn)的好方法。此外,GWT Designer 還內建了所見即所得的 CSS 編輯器。
- Quick Fix 和警告訊息幫助你把 GWT 寫的又快又好。舉例來說,當你建立一個 extend GWT RemoteService 這個 class 的 interface,GPE 會提醒你建立 GWT-RPC 所需對應的 async interface。在紅色錯誤訊息按下 Ctrl+1(Quick Fix),就能解決了。
- Dev mode 與 GPE 的整合可以讓你快速地測試程式碼。Run As→Web Application,會啟動 GWT 的 development mode 以及(如果適用)App Engine dev server,你就可以在 browser 上測試成果。當 dev mode 啟動,在 Development Mode 的 tab 中找尋 URL 並在上頭點兩下,就會在預設的 browser 中啟動你的程式。在 GWT dev mode 執行時,你可以改變 Java 碼,然後在 browser 上頭按下 refresh,你會馬上看到對應的變化。
- 在 dev mode 中除錯。在 Eclipse 中設定一個中斷點,然後在 project 上按下右鍵→Debug As→Web Application。切換到 browser 並執行程式。Eclipse 會打開 Debug perspective,你就可以逐行執行程式、檢查變數.....等等。
- 按一次鍵就 deploy 到 GAE。按下工具列的 Google App Engine 標誌,你就知道啦。
- 支援 Maven 。GPE 透過 m2eclipse 來使用 Maven project(見安裝說明)。把一個 Maven project(例如用 GWT+GAE 寫的開支經費範例)check out 進你的 workspace,然後按下 File→Import→Existing maven project,並指定到 pom.xml 檔案。Maven 會下載所有 POM 需要的 jar 檔與 plugin,GPE 會根據 POM 來設定 GWT project 以及 App Engine SDK。你可以從外部執行 Maven 指令,或是在 Eclipse 用 Run As→Web Application 來執行。
- 測試。Run As→GWT Junit Test 讓你輕易地執行 extend GWTTestCase 的測試案例。
- SpeedTracer。你可以在 Eclipse 中啟動 SpeedTracer。按下 GPE 工具列上頭的綠色碼表按鈕,GPE 會 compile、執行你的 application,並在 Chrome 中啟動 SpeedTracer 來監控你的 application。
還沒試過這些東西嗎?馬上就安裝 GPE 吧!
2011-04-23
App Engine 1.4.3 版釋出
原文網址:http://googleappengine.blogspot.com/2011/03/announcing-app-engine-143-release_30.html
就在春天,我們提供一個新的 App Engine 版本,讓 Java 與 Python 的運作狀況更為接近。Python 方面,我們已經推出了測試的 library 來滿足現有的 Java 測試 framework;Java 方面則引入了 Deferred 與 Remote 這兩個 API。此版本還引入了一個新的 Blobstore 寫入方式、Python 版的實驗性質 Prospective Search API,以及一些 Task Queue 與 Cron 的好東西。
Python
Java
新的 API
service 變更
即將推出...
最後,我們要預告 1.4.4 版。在 1.4.0 當中,我們引入「讓使用者下載已經 deploy 到 App Engine 的程式碼」這個功能。1.4.2 版中,我們發表了 admin role 讓擁有者也能下載。在 1.4.4 版中,我們預計改變讓上傳程式碼的人跟(列在 Admin Console 中的) project 擁有者都能下載。 為了這個功能而作準備,一定要確保有在 Admin Console 當中妥善地對 每個開發者指定 role。或者,你仍然可以永久關閉下載程式碼這個功能。
就這些了,如果要了解更多資訊,請閱讀完整的 release note,包括 Java 版和 Python 版的所有新的功能和問題修正 。歡迎所有鼓勵與回饋的意見。
就在春天,我們提供一個新的 App Engine 版本,讓 Java 與 Python 的運作狀況更為接近。Python 方面,我們已經推出了測試的 library 來滿足現有的 Java 測試 framework;Java 方面則引入了 Deferred 與 Remote 這兩個 API。此版本還引入了一個新的 Blobstore 寫入方式、Python 版的實驗性質 Prospective Search API,以及一些 Task Queue 與 Cron 的好東西。
Python
- Prospective Search API:實驗性質的 Prospective Search API 允許 Python 用戶在寫入符合特定條件數據時,偵測到並有所反應。在這個實驗性質的版本中,使用者可以執行 10000 次 Prospective Search API 的 subscription 。至於價錢會在完整啟用後再次公告。
- Testbed 單元測試 framework:給 Python 使用的 Testbed 套件提供了一個簡單的 interface 讓使用 App Engine API 可以像已經存在的 Java 測試 framework 一樣整合。你不用依賴呼叫 App Engine 的 production service 就能為你的 application 建立測試,因而加速完成測試以及消除與外部 service 的相依性。在 Google 裡頭有廣為人知的測試文化,我們希望這個 API 會讓你更快地開發更穩定的程式碼。
Java
- Concurrent Request:直到現在,Java application 仍依賴啟動額外的 instance 來動態擴展以應付更高的流量。現在,concurrent request 讓每個 application 可以同時處理多個使用者的 request。開始使用前,請先確保你的 application 程式是 threadsafe,然後在 appengine-web.xml 當中加入
來啟動 concurrent request。 - Java Remote API 與 Deferred API:Remote API 和 Deferred API 這兩個 library 在 Python 版已經支持一段時間了,現在也可以在 Java 上頭用了!remote API 讓你可以在自己的機器上頭操作 application 的 datastore。這對於並不完全符合 App Engine 的 request/response model 的作品特別有用。Deferred API 讓使用者可以更簡單撰寫與執行 ad hoc 的 task。我們的文件當中包含了更多的資訊以及範例,告訴你如何在 Java 版的 App Engine 當中使用這兩個 API。
新的 API
- File API:新的 File API(Python 版與 Java 版)讓你可以用程式讀寫 Blobstore 中的資料。這個 API 可以用來產生報告、匯出資料、或是任何你想要對二進位大檔所作的操作。
service 變更
- 更新 Task Queue 與 Cron:我們已經滿足一些 Task Queue 與 Cron 上頭的優先需求。在此版本中,你可以設定 task queue 或是 cron 對特定的 application 版本發出 request。想要用像「11:00~17:00 之間每隔五分鐘(every 5 minutes from 11:00 to 17:00)」這種區間語法嗎?現在 1.4.3 版也提供啦。最後還有一點,Admin Console 的 Task Queue 頁面現在對 queue 包含超過兩千個 task 的 queue 可以顯示更精確估算 queue 的大小。
即將推出...
最後,我們要預告 1.4.4 版。在 1.4.0 當中,我們引入「讓使用者下載已經 deploy 到 App Engine 的程式碼」這個功能。1.4.2 版中,我們發表了 admin role 讓擁有者也能下載。在 1.4.4 版中,我們預計改變讓上傳程式碼的人跟(列在 Admin Console 中的) project 擁有者都能下載。 為了這個功能而作準備,一定要確保有在 Admin Console 當中妥善地對 每個開發者指定 role。或者,你仍然可以永久關閉下載程式碼這個功能。
就這些了,如果要了解更多資訊,請閱讀完整的 release note,包括 Java 版和 Python 版的所有新的功能和問題修正 。歡迎所有鼓勵與回饋的意見。
2011-02-28
發表 App Engine 的 High Replication Datastore
原文網址:http://googleappengine.blogspot.com/2011/01/announcing-high-replication-datastore.html
當 App Engine 問世兩年後,我們提供設計成快速、strongly consistent 讀取的 Datastore。它是架構在 Master/Slave 式的 replication 拓樸,設計為快速寫入、同時允許 application 可以馬上看到寫入後的資料。你可能有聽說,過去六個月我們一直在設法解決一些 App Engine 上 Datastore 的可靠性問題在過去幾個月,我們在修復這些問題方面有了重大進展。然後,處理這些問題的經驗讓我們重新思考一些設計上的假設。正如我們在年初時在 outage report 當中承諾的,我們想要更徹底地解決這個問題。
今天,我們很自豪地發表一個新的 Datastore 設定選項:High Replication Datastore。因應寫入及變更資料時 API 保證一致性所增加的延遲成本,High Replication Datastore 提供最高等級的讀寫能力。High Replication Datastore 增加了維護資料副本的 data center 數量,並使用 Paxos 演算法來讓 data center 之間的資料能立即保持一致性。其中最顯著的優點,就是在預期內的維護期間、以及大多數預期外的 infrastructure 問題上,你的 application 都會保有完整的功能。我們的文件中將更仔細的比較這兩個選項。
從現在開始,當建立一個新的 application 時,你可以選擇 Datastore 的設定。雖然目前的 Datastore 設定預設值為 Master/Slave,以後可能會改變。
Datastore 的設定選項在 applcation 建立後就不能更改,而所有已經存在的 application 都是用 Master/Slave 設定。我們提供了一些遷移工具來幫助既有 application 上的資料改使用 High Replication Datastore。首先,我們在 Admin Console 增加了一個選項,讓 application 變成唯讀模式,這樣一來資料就可以確實地在 application 之間複製。其次,我們用 Python SDK 提供了一個遷移工具,讓你將一個 application 複製到另一個去。Python 與 Java 的 application 要如何使用這個工具的文件在這裡。
現在提一下關於價格的事情:因為 High Replication 會明顯地增加資料複製量,所以價格也就會不一樣。不過,我們相信這個新的設定對於一些 application 來說會顯著改良,所以我們希望儘快的提供這個功能——即使我們還沒有決定價格的細節。因此,在 2011.07 之前,我們把 High Replication Datastore 的價格定為 Master/Slave Datastore 的三倍。七月以後,我們預計會改變這個價格。我們將會儘快讓你知道價格的詳細內容,也請記得當價格變動時,你始終被服務條款所保護。由於成本較高,我們建議 High Replication Datastore 主要是用在要有最高等級可用性的特定 application 上。
(譯註:原文最後一段懶得翻譯... [逃])
當 App Engine 問世兩年後,我們提供設計成快速、strongly consistent 讀取的 Datastore。它是架構在 Master/Slave 式的 replication 拓樸,設計為快速寫入、同時允許 application 可以馬上看到寫入後的資料。你可能有聽說,過去六個月我們一直在設法解決一些 App Engine 上 Datastore 的可靠性問題在過去幾個月,我們在修復這些問題方面有了重大進展。然後,處理這些問題的經驗讓我們重新思考一些設計上的假設。正如我們在年初時在 outage report 當中承諾的,我們想要更徹底地解決這個問題。
今天,我們很自豪地發表一個新的 Datastore 設定選項:High Replication Datastore。因應寫入及變更資料時 API 保證一致性所增加的延遲成本,High Replication Datastore 提供最高等級的讀寫能力。High Replication Datastore 增加了維護資料副本的 data center 數量,並使用 Paxos 演算法來讓 data center 之間的資料能立即保持一致性。其中最顯著的優點,就是在預期內的維護期間、以及大多數預期外的 infrastructure 問題上,你的 application 都會保有完整的功能。我們的文件中將更仔細的比較這兩個選項。
從現在開始,當建立一個新的 application 時,你可以選擇 Datastore 的設定。雖然目前的 Datastore 設定預設值為 Master/Slave,以後可能會改變。
 |
| 建立 application 時的 Datastore 設定 |
現在提一下關於價格的事情:因為 High Replication 會明顯地增加資料複製量,所以價格也就會不一樣。不過,我們相信這個新的設定對於一些 application 來說會顯著改良,所以我們希望儘快的提供這個功能——即使我們還沒有決定價格的細節。因此,在 2011.07 之前,我們把 High Replication Datastore 的價格定為 Master/Slave Datastore 的三倍。七月以後,我們預計會改變這個價格。我們將會儘快讓你知道價格的詳細內容,也請記得當價格變動時,你始終被服務條款所保護。由於成本較高,我們建議 High Replication Datastore 主要是用在要有最高等級可用性的特定 application 上。
(譯註:原文最後一段懶得翻譯... [逃])
2011-02-26
App Engine SDK 1.4.2 更新版
原文網址:http://googleappengine.blogspot.com/2011/02/app-engine-142-sdk-api-updates-and.html
現在才二月,我們就已經發表今年第二次更新啦!請到這裡下載。1.4.2 版著重於改善和更新現有的幾個 App Engine API。
加強 XMPP API 讓 application 與使用者之間有更好的互動。當使用者登入、登出或作其他狀態的改變時會發出通知,且 application 可以立刻設定 presence 細節然後回傳給使用者。Subscription 跟 Presence 的通知啟用方式就像 application 設定中的 inbound 服務。
Task Queue 效能提昇與 Task Queue API 改良。首先,我們把每秒可以執行的 task 加大到 100 個。 application 也可以針對目前的 request 在個別的 queue 的設定檔當中指定最大值。這讓你可以更輕鬆地掌控 task queue 消耗了多少資源。我們還添加了一個 API,讓你以程式的方式刪除 task,而不用到 Admin Console 裡頭手動管理。
一如往常,有許多功能與議題也做了修正,例如 JAX-WS 的支援(可參見如何在 App Engine application 中建立 SOAP),當然也支援了 Django 1.2,所以請你一定要讀一下 Java 與 Python 的更新說明。我們還更新了 App Engine 的展望圖,加了一些新的專案,所以去看看吧!。如果您有任何意見想反應,歡迎到 App Engine 社群。
現在才二月,我們就已經發表今年第二次更新啦!請到這裡下載。1.4.2 版著重於改善和更新現有的幾個 App Engine API。
加強 XMPP API 讓 application 與使用者之間有更好的互動。當使用者登入、登出或作其他狀態的改變時會發出通知,且 application 可以立刻設定 presence 細節然後回傳給使用者。Subscription 跟 Presence 的通知啟用方式就像 application 設定中的 inbound 服務。
Task Queue 效能提昇與 Task Queue API 改良。首先,我們把每秒可以執行的 task 加大到 100 個。 application 也可以針對目前的 request 在個別的 queue 的設定檔當中指定最大值。這讓你可以更輕鬆地掌控 task queue 消耗了多少資源。我們還添加了一個 API,讓你以程式的方式刪除 task,而不用到 Admin Console 裡頭手動管理。
一如往常,有許多功能與議題也做了修正,例如 JAX-WS 的支援(可參見如何在 App Engine application 中建立 SOAP),當然也支援了 Django 1.2,所以請你一定要讀一下 Java 與 Python 的更新說明。我們還更新了 App Engine 的展望圖,加了一些新的專案,所以去看看吧!。如果您有任何意見想反應,歡迎到 App Engine 社群。
回函照登 1
主題:
回函照登
> hi PT2 團長:
> 在網路上看到你的文章,有關於GWT
> 冒昧相問,事實上對於 client 的 widget & object boundle 一直有很大的問題
我不太確定你的文法到底是想要表達啥
為甚麼 widget 跟 object 要 b"u"ndle 在一起
如果你要講的是某個你無法控制的(例如 3rd party library) class
要透過 GWT RPC 給 gwt 寫的 client 使用
那麼,是要透過轉換的沒錯(我書念得不多,不知道 helper 的意思)
Google 的說法是把這種 class 叫做 DTO
> 目前我們是要寫一個helper 來轉換
> 請問團長 有什麼建議的方法嗎?
如果你(也)是用 AppEngine,那可以考慮用 Objectify
另外,GWT 2.0 之後 RequestFactory 我不確定用途(是說也不太想用)
跟這個議題也許有點關係,你可以到「長草的筆記本」那裡找資料當課外讀物玩玩看
我只知道這些
> 另 1.6.4 想升到2.2 ,能不能呢 ?
為甚麼不能?
> 我自己試過從1.6 升1.7就掛光光了,頭燒到最後,只好放棄
> 感謝團長
請描述解釋闡明你的「掛光光」
不然你可能去龍山寺拜拜或是隔壁地下街找算命師會比較快
http://blog.psmonkey.org/2008/09/blog-post.html
> 在網路上看到你的文章,有關於GWT
> 冒昧相問,事實上對於 client 的 widget & object boundle 一直有很大的問題
我不太確定你的文法到底是想要表達啥
為甚麼 widget 跟 object 要 b"u"ndle 在一起
如果你要講的是某個你無法控制的(例如 3rd party library) class
要透過 GWT RPC 給 gwt 寫的 client 使用
那麼,是要透過轉換的沒錯(我書念得不多,不知道 helper 的意思)
Google 的說法是把這種 class 叫做 DTO
> 目前我們是要寫一個helper 來轉換
> 請問團長 有什麼建議的方法嗎?
如果你(也)是用 AppEngine,那可以考慮用 Objectify
另外,GWT 2.0 之後 RequestFactory 我不確定用途(是說也不太想用)
跟這個議題也許有點關係,你可以到「長草的筆記本」那裡找資料當課外讀物玩玩看
我只知道這些
> 另 1.6.4 想升到2.2 ,能不能呢 ?
為甚麼不能?
> 我自己試過從1.6 升1.7就掛光光了,頭燒到最後,只好放棄
> 感謝團長
請描述解釋闡明你的「掛光光」
不然你可能去龍山寺拜拜或是隔壁地下街找算命師會比較快
http://blog.psmonkey.org/2008/09/blog-post.html
2011-02-21
Eclipse 的 Google Plugin 及 GWT 2.2 版問世
原文網址:http://googlewebtoolkit.blogspot.com/2011/02/google-plugin-for-eclipse-and-gwt-22.html
我們很高興在這裡分享 Eclipse 的 Google Plugin(以下簡稱 GPE)和 GWT 2.2 版 提供的幾個新功能。首先,GPE 把 GWT Designer 這個強大的 WYSISYG Ajax UI 設計工具整合進來。這可以讓你更簡單快速地建立 UI。其二,GWT SDK 支援初步的 HTML5 規格,讓開發者獲得現代 web 的優勢。此外,GWT 的 CellTable widget 現在提供了新的功能,可以設定預設的排序欄位、設定欄位寬度等。這些新的特性可以讓你用 Java 工具與 Eclipse 更簡單地做出超優的 web application。雖然這些 application 可以在任何平台上運作,不過 GPE 對於 Google App Engine 上的 deploy 與執行更為方便。
安裝 Eclipse 的 Google Plugin 以及 GWT SDK 的介紹可以在 GPE 入門裡頭找到。
如果只是單純想找 GWT 2.2 SDK,就在這裡頭。
GWT Designer
將 GWT Designer 直接整合進 Eclipse 的 Google Plugin 中,是過去幾個月的首要工作。我們從社群中得到很積極的意見回饋,在這個版本當中,我們不只要提供 GWT Designer 的最佳開發經驗,也要讓 GWT Designer 與 GPE 整合地天衣無縫。

HTML5 的功能
GWT 2.2 版支援特定的 HTML5 功能,例如 Canvas 可以讓你用 script 動態繪製 2D 圖形或 bitmap 圖,以及嵌入影音的 tag。這些 API 仍在實驗中,有可能在接下來的幾個版本中會有所改變,但我們覺得已經穩定到可以提供一些實質好處。下面式一個 GWT 團隊成員做的一個 demo,展示 GWT SDK 中對 Canvas 的支援。你可以在這裡找到這個 demo 的程式碼: http://code.google.com/p/gwtcanvasdemo/ 。
新的 CellTable API
在 GWT 2.1 版時,我們發現很多開發者常常在案子裡使用了 CellTable 這個 widget,然後馬上就貼上同樣的程式碼好加上 sort 功能,接著就不辭辛苦地設定欄位的寬度。到了 GWT 2.2 版,這些功能已經變成 CellTable 本身的一部分啦。我們可以、也想要加強原生的 GWT widget,增添功能以盡可能減少開發者必須自己撰寫的程式碼。
如果你想實際看這些更新的話,GWT Showcase 的 CellTable 範例裡頭有。

關於 Java 1.5
GWT 2.2 版將(僅)廢止 Java 1.5 的支援,這會導致 build application 時會出現警告訊息。 雖然 Java 1.5 仍然可以搭配這個版本的 GWT,開發者還是應該升級 Java 來消除這些警告、並確保未來 GWT 版本的相容性。
我們很樂意聽到你所提出的問題或是意見回饋,可以的話就到 Google Web Toolkit Group 來暢所欲言吧!
我們很高興在這裡分享 Eclipse 的 Google Plugin(以下簡稱 GPE)和 GWT 2.2 版 提供的幾個新功能。首先,GPE 把 GWT Designer 這個強大的 WYSISYG Ajax UI 設計工具整合進來。這可以讓你更簡單快速地建立 UI。其二,GWT SDK 支援初步的 HTML5 規格,讓開發者獲得現代 web 的優勢。此外,GWT 的 CellTable widget 現在提供了新的功能,可以設定預設的排序欄位、設定欄位寬度等。這些新的特性可以讓你用 Java 工具與 Eclipse 更簡單地做出超優的 web application。雖然這些 application 可以在任何平台上運作,不過 GPE 對於 Google App Engine 上的 deploy 與執行更為方便。
安裝 Eclipse 的 Google Plugin 以及 GWT SDK 的介紹可以在 GPE 入門裡頭找到。
如果只是單純想找 GWT 2.2 SDK,就在這裡頭。
GWT Designer
將 GWT Designer 直接整合進 Eclipse 的 Google Plugin 中,是過去幾個月的首要工作。我們從社群中得到很積極的意見回饋,在這個版本當中,我們不只要提供 GWT Designer 的最佳開發經驗,也要讓 GWT Designer 與 GPE 整合地天衣無縫。

HTML5 的功能
GWT 2.2 版支援特定的 HTML5 功能,例如 Canvas 可以讓你用 script 動態繪製 2D 圖形或 bitmap 圖,以及嵌入影音的 tag。這些 API 仍在實驗中,有可能在接下來的幾個版本中會有所改變,但我們覺得已經穩定到可以提供一些實質好處。下面式一個 GWT 團隊成員做的一個 demo,展示 GWT SDK 中對 Canvas 的支援。你可以在這裡找到這個 demo 的程式碼: http://code.google.com/p/gwtcanvasdemo/ 。
新的 CellTable API
在 GWT 2.1 版時,我們發現很多開發者常常在案子裡使用了 CellTable 這個 widget,然後馬上就貼上同樣的程式碼好加上 sort 功能,接著就不辭辛苦地設定欄位的寬度。到了 GWT 2.2 版,這些功能已經變成 CellTable 本身的一部分啦。我們可以、也想要加強原生的 GWT widget,增添功能以盡可能減少開發者必須自己撰寫的程式碼。
如果你想實際看這些更新的話,GWT Showcase 的 CellTable 範例裡頭有。

關於 Java 1.5
GWT 2.2 版將(僅)廢止 Java 1.5 的支援,這會導致 build application 時會出現警告訊息。 雖然 Java 1.5 仍然可以搭配這個版本的 GWT,開發者還是應該升級 Java 來消除這些警告、並確保未來 GWT 版本的相容性。
我們很樂意聽到你所提出的問題或是意見回饋,可以的話就到 Google Web Toolkit Group 來暢所欲言吧!
2011-02-01
GWT 不適合開發 HTML5 上的遊戲
原文網址:http://my2iu.blogspot.com/2011/01/gwt-isnt-good-environment-for-html5.html
譯者註:這篇並沒有寫的很好,甚至後兩段已經脫離主題,變成是在思考 JavaScript 的 coding style 與 IDE 協助開發的問題。不過頭幾段倒是給我們一些關於 GWT browser plugin 的運作原理與問題,故潦草一翻,順便當成是腦力復健 [慘笑]
去年我在 XNA 上頭寫了一個小遊戲,因為沒人玩,所以我開始把它轉換成使用 HTML5 特性的網頁遊戲。最初遊戲是用 C# 寫的,若要將它網頁化,我覺得最簡單的方法是用 Java 改寫,然後用 GWT 轉成 JavaScript。GWT 是一組 Google 提供的工具,讓你可以用 Java 寫網頁,然後它會把程式碼轉換成跨 browser 的 JavaScript 碼。
在快速看過 GWT UI frame,我發現這遠比預期的好上很多。不過很可惜的是,我發現目前 GWT 2.0 版在開發 HTML5 的遊戲方面,並沒辦法運作的很好。問題在於 development mode 中,GWT 並沒有實際將程式碼轉成 JavaScript。它會以 Java 的方式執行,然後使用一個中介層來轉換成 JavaScript ojbect 或是 browser 的 DOM,並將結果轉換回 Java 裡。起初我以為這沒啥影響,因為只有在呼叫一卡車 DOM API 或是因為某些原因要儲存一堆東西在 JavaScript object 當中,這才會是個問題。偏偏在我的 HTML5 遊戲當中就都遇到了 Orz。我在 HTML5 的 canvas 上畫了一堆東西,需要呼叫一堆 API。我也使用 JSON 來儲存遊戲資料,也就是說要用 JavaScript object 的形式存一堆東西。
結果就是,在 development mode 當中,我的遊戲執行速度慢到爆炸。這在 Chrome 上特別嚴重,因為 sandbox 的設計讓 Chrome 的 GWT development plugin 在 browser 跟 Java code 之間轉換特別慢。如果換到 Firefox 上頭就還能忍受,不過我發現我最佳化的方向有誤。看起來似乎在 development mode 才會跑的很慢(像是用 JSON 作遊戲存檔超慢讓 browser 噴了 timeout),如果實際 compile 成 JavaScript 就會很跑的很快。將 Java 碼轉換到 browser JavaScript 引擎上運作的負擔,讓開發人員很難確定遊戲實際跑起來會是啥樣子。
我明白為甚麼 GWT 會設計成這樣。JavaScript debugger API 可以讓 GWT 這類的工具將 JavaScript 碼的行數跟變數與程式設計師寫的 Java 碼作對應,但是大多數的 browser 並沒有公開這類 API。好在像 Firefox 這類的 browser 變得越來越成熟而有這類的 API,所以我期待未來有人可以重寫 GWT,可以在 development mode 時實際轉換 Java 碼變成 JavaScript,而且還是可以作 debug。
在這段期間,我會用 GWT 完成我的遊戲,然後回頭寫純 JavaScript 遊戲。我發現 JavaScript 的自由格式、非結構化性質是沒啥生產力的,但我也疑惑 Java 的 static type 會是解決這問題的最好方法嗎?當我在寫 Smalltalk 時,所有東西都可以是 dynamic type,但寫起來還是相當有效率。Smalltalk 把程式碼用很結構化的方式組織起來,所以讀程式碼或是在裡頭找東西都很容易。到目前為止,我寫的 JavaScript 程式碼風格太自由了,導致即使搭配 JDST 的 Eclipse 也無法分析的很好,只能用簡單的方法瀏覽程式碼。也許我該嘗試用比較結構的方法來寫程式,然後找看看是否有合適的編輯器可以建立出有用的架構,從而讓我讀寫 JavaScript 碼時更有效率。
譯者註:這篇並沒有寫的很好,甚至後兩段已經脫離主題,變成是在思考 JavaScript 的 coding style 與 IDE 協助開發的問題。不過頭幾段倒是給我們一些關於 GWT browser plugin 的運作原理與問題,故潦草一翻,順便當成是腦力復健 [慘笑]
去年我在 XNA 上頭寫了一個小遊戲,因為沒人玩,所以我開始把它轉換成使用 HTML5 特性的網頁遊戲。最初遊戲是用 C# 寫的,若要將它網頁化,我覺得最簡單的方法是用 Java 改寫,然後用 GWT 轉成 JavaScript。GWT 是一組 Google 提供的工具,讓你可以用 Java 寫網頁,然後它會把程式碼轉換成跨 browser 的 JavaScript 碼。
在快速看過 GWT UI frame,我發現這遠比預期的好上很多。不過很可惜的是,我發現目前 GWT 2.0 版在開發 HTML5 的遊戲方面,並沒辦法運作的很好。問題在於 development mode 中,GWT 並沒有實際將程式碼轉成 JavaScript。它會以 Java 的方式執行,然後使用一個中介層來轉換成 JavaScript ojbect 或是 browser 的 DOM,並將結果轉換回 Java 裡。起初我以為這沒啥影響,因為只有在呼叫一卡車 DOM API 或是因為某些原因要儲存一堆東西在 JavaScript object 當中,這才會是個問題。偏偏在我的 HTML5 遊戲當中就都遇到了 Orz。我在 HTML5 的 canvas 上畫了一堆東西,需要呼叫一堆 API。我也使用 JSON 來儲存遊戲資料,也就是說要用 JavaScript object 的形式存一堆東西。
結果就是,在 development mode 當中,我的遊戲執行速度慢到爆炸。這在 Chrome 上特別嚴重,因為 sandbox 的設計讓 Chrome 的 GWT development plugin 在 browser 跟 Java code 之間轉換特別慢。如果換到 Firefox 上頭就還能忍受,不過我發現我最佳化的方向有誤。看起來似乎在 development mode 才會跑的很慢(像是用 JSON 作遊戲存檔超慢讓 browser 噴了 timeout),如果實際 compile 成 JavaScript 就會很跑的很快。將 Java 碼轉換到 browser JavaScript 引擎上運作的負擔,讓開發人員很難確定遊戲實際跑起來會是啥樣子。
我明白為甚麼 GWT 會設計成這樣。JavaScript debugger API 可以讓 GWT 這類的工具將 JavaScript 碼的行數跟變數與程式設計師寫的 Java 碼作對應,但是大多數的 browser 並沒有公開這類 API。好在像 Firefox 這類的 browser 變得越來越成熟而有這類的 API,所以我期待未來有人可以重寫 GWT,可以在 development mode 時實際轉換 Java 碼變成 JavaScript,而且還是可以作 debug。
在這段期間,我會用 GWT 完成我的遊戲,然後回頭寫純 JavaScript 遊戲。我發現 JavaScript 的自由格式、非結構化性質是沒啥生產力的,但我也疑惑 Java 的 static type 會是解決這問題的最好方法嗎?當我在寫 Smalltalk 時,所有東西都可以是 dynamic type,但寫起來還是相當有效率。Smalltalk 把程式碼用很結構化的方式組織起來,所以讀程式碼或是在裡頭找東西都很容易。到目前為止,我寫的 JavaScript 程式碼風格太自由了,導致即使搭配 JDST 的 Eclipse 也無法分析的很好,只能用簡單的方法瀏覽程式碼。也許我該嘗試用比較結構的方法來寫程式,然後找看看是否有合適的編輯器可以建立出有用的架構,從而讓我讀寫 JavaScript 碼時更有效率。
訂閱:
文章 (Atom)